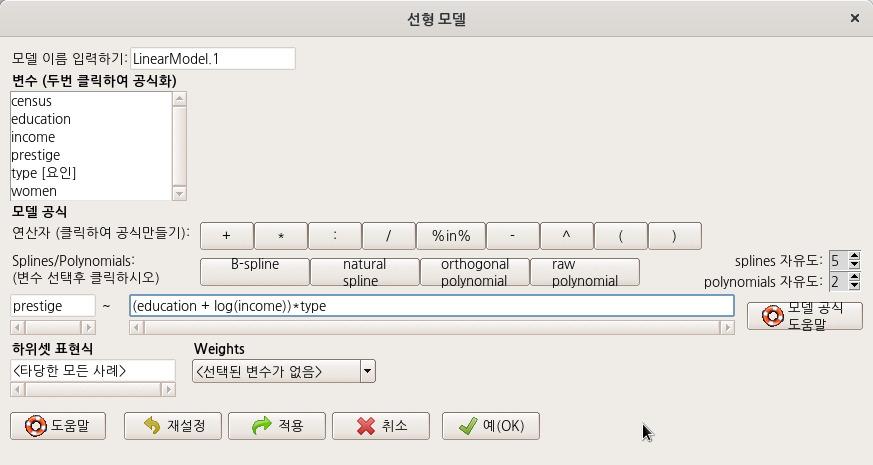
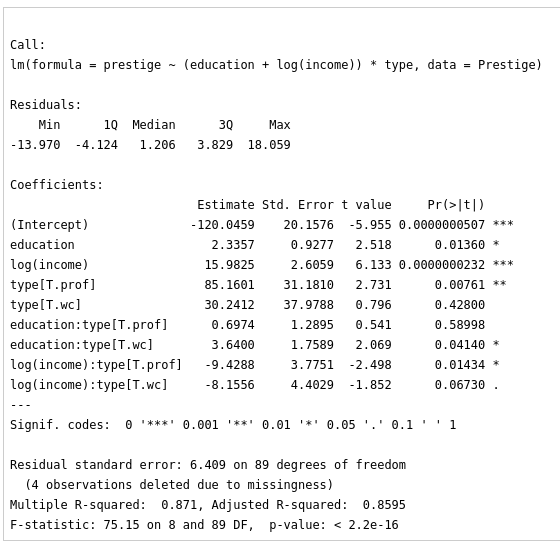
datasets::sleep


data(sleep, package="datasets")
summary(sleep)
str(sleep)
데이터셋의 내부는 다음과 같다:

| sleep {datasets} | R Documentation |
Student's Sleep Data
Description
Data which show the effect of two soporific drugs (increase in hours of sleep compared to control) on 10 patients.
Usage
sleepFormat
A data frame with 20 observations on 3 variables.
| [, 1] | extra | numeric | increase in hours of sleep |
| [, 2] | group | factor | drug given |
| [, 3] | ID | factor | patient ID |
Details
The group variable name may be misleading about the data: They represent measurements on 10 persons, not in groups.
Source
Cushny, A. R. and Peebles, A. R. (1905) The action of optical isomers: II hyoscines. The Journal of Physiology 32, 501–510.
Student (1908) The probable error of the mean. Biometrika, 6, 20.
References
Scheffé, Henry (1959) The Analysis of Variance. New York, NY: Wiley.
Examples
require(stats)
## Student's paired t-test
with(sleep,
t.test(extra[group == 1],
extra[group == 2], paired = TRUE))
## The sleep *prolongations*
sleep1 <- with(sleep, extra[group == 2] - extra[group == 1])
summary(sleep1)
stripchart(sleep1, method = "stack", xlab = "hours",
main = "Sleep prolongation (n = 10)")
boxplot(sleep1, horizontal = TRUE, add = TRUE,
at = .6, pars = list(boxwex = 0.5, staplewex = 0.25))
'Dataset_info > sleep' 카테고리의 다른 글
| sleep 데이터셋 예제 (0) | 2022.06.25 |
|---|