통계 > 요약 > 정규성을 향해서 변환시키기...
Statistics > Summaries > Transform toward normaltiy...
어느 데이터셋을 활성화시키면, '통계 > 요약 > 정규성을 향해서 변환시키기...' 메뉴 기능이 아래와 같이 활성화될 것이다.

carData 패키지에 포함된 Prestige 데이터셋을 이용하여 연습해보자.
'데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택한후 carData 패키지에 있는 Prestige 데이터셋을 찾아서 선택한다. 그러면, R Commander 상단에 있는 <활성 데이터셋 없음> 이라는 버튼이 'Prestige'로 바뀌면서 '통계 > 요약 > 정규성을 향해서 변환하기...' 메뉴 기능을 이용할 수 있게 된다. 이 메뉴를 선택한다. 그러면, 아래와 같은 화면이 등장한다. Prestige 데이터셋에서 정규성을 향해서 변환시킬 변수를 선택하는 메뉴 창인데, income 변수를 선택해보자.

car 패키지에 포함된 powerTransform() 함수를 사용하여 출력창에 아래와 같은 결과를 생산한다. 출력내용에서 'Est Power'값으로 제시하는 0.1793을 확인한다. Prestige 패키지에 있는 income 변수에 0.1793 승(제곱)을 하면, 그 사례 값들은 정규 분포적 특성으로 변환될 수 있다는 의미이다.

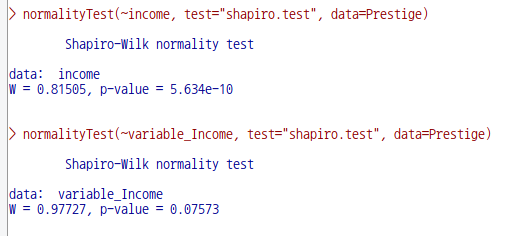
'통계 > 요약 > 정규성 검정...' 메뉴 기능이 있다. 이 기능을 사용하여, Prestige 데이터셋의 income 변수와 정규성을 향해서 변환된 income 변수의 새로운 변수, 편의상 variable_Income,의 정규성 검정을 시도해보자.
8. Test of normality...
통계 > 요약 > 정규성 검정... Statistics > Summaries > Test of normality... 수치형(numeric, integer) 변수들 중에서 하나를 선택한다. 기본 설정에 Shapiro-Wilk의 정규성 검정법이 선택되어 있다. 수입(연..
rcmdr.kr
먼저, 변환된 변수를 Prestige 데이터셋에 추가해야 한다. '데이터 > 활성 데이터셋에 있는 변수 관리하기 > 새로운 변수 계산하기...' 메뉴 기능을 통하여 income 변수가 변환된 variable_Income 변수를 만들어보자. '계산 표현식'에 income^0.1793이 입력된 것을 확인한다. 여기서 0.1793은 powerTransform() 함수를 통하여 앞서 추출한 income 변수의 승(제곱) 값이다.

Prestige 데이터셋에 variable_Income 이라는 새로운 변수가 추가된다. 이제 '통계 > 요약 > 정규성 검정...' 메뉴 기능을 선택하고, 차례로 두번의 정규성 검정을 진행한다. 첫번째는 income 변수로, 두번째는 variable_Income변수를 선택한다. 두개의 정규성 검정 결과를 비교하기 위해서다. 아래 화면은 두번째 검정, variable_Income 변수를 선택하는 메뉴 창이다.

두번의 정규성 검정에서 제시하는 유의 확률값을 살펴보자. variable_Income 변수의 정규성 검정 결과는 p-value=0.07573으로 variable _income 변수는 정규분포적 특징을 갖는다고 할 수 있다.
?powerTransform # car 패키지의 powerTransform 도움말 보기
# Box Cox Method, univariate
summary(p1 <- powerTransform(cycles ~ len + amp + load, Wool))
# fit linear model with transformed response:
coef(p1, round=TRUE)
summary(m1 <- lm(bcPower(cycles, p1$roundlam) ~ len + amp + load, Wool))
# Multivariate Box Cox uses Highway1 data
summary(powerTransform(cbind(len, adt, trks, sigs1) ~ 1, Highway1))
# Multivariate transformation to normality within levels of 'htype'
summary(a3 <- powerTransform(cbind(len, adt, trks, sigs1) ~ htype, Highway1))
# test lambda = (0 0 0 -1)
testTransform(a3, c(0, 0, 0, -1))
# save the rounded transformed values, plot them with a separate
# color for each highway type
transformedY <- bcPower(with(Highway1, cbind(len, adt, trks, sigs1)),
coef(a3, round=TRUE))
## Not run: scatterplotMatrix( ~ transformedY|htype, Highway1)
# With negative responses, use the bcnPower family
m2 <- lm(I1L1 ~ pool, LoBD)
summary(p2 <- powerTransform(m2, family="bcnPower"))
testTransform(p2, .5)
summary(powerTransform(update(m2, cbind(LoBD$I1L2, LoBD$I1L1) ~ .), family="bcnPower"))
## Not run:
# takes a few seconds:
# multivariate bcnPower, with 8 responses
summary(powerTransform(update(m2, as.matrix(LoBD[, -1]) ~ .), family="bcnPower"))
# multivariate bcnPower, fit with one iteration using starting values as estimates
summary(powerTransform(update(m2, as.matrix(LoBD[, -1]) ~ .), family="bcnPower", itmax=1))
## End(Not run)
# mixed effects model
## Not run:
# uses the lme4 package
data <- reshape(LoBD[1:20, ], varying=names(LoBD)[-1], direction="long", v.names="y")
names(data) <- c("pool", "assay", "y", "id")
data$assay <- factor(data$assay)
require(lme4)
m2 <- lmer(y ~ pool + (1|assay), data)
summary(l2 <- powerTransform(m2, family="bcnPower", verbose=TRUE))
## End(Not run)'Statistics > Summaries' 카테고리의 다른 글
| 8. Test of normality... (0) | 2022.02.13 |
|---|---|
| 7. Correlation test... (0) | 2022.02.13 |
| 6. Correlation matrix... (0) | 2022.02.13 |
| 5. Table of Statistics... (0) | 2022.02.13 |
| 4. Count missing observations (0) | 2022.02.13 |