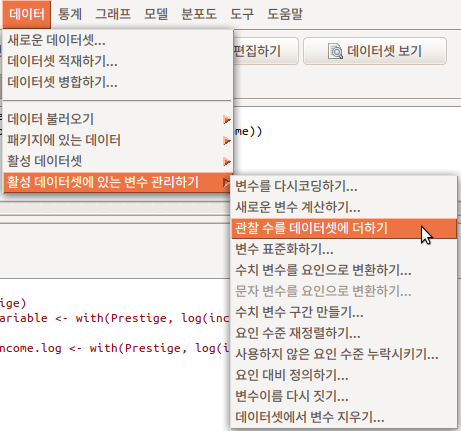
데이터 > 활성 데이터셋의 변수 관리하기 > 요인 대비 정의하기...
Data > Manage variables in active data set > Define contrasts for a factor...

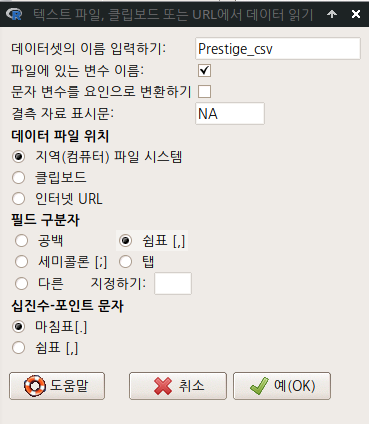
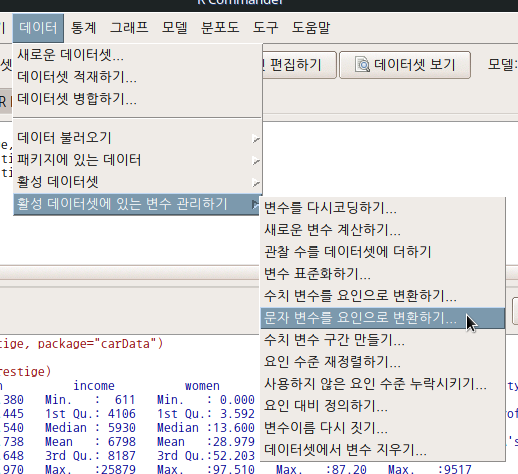
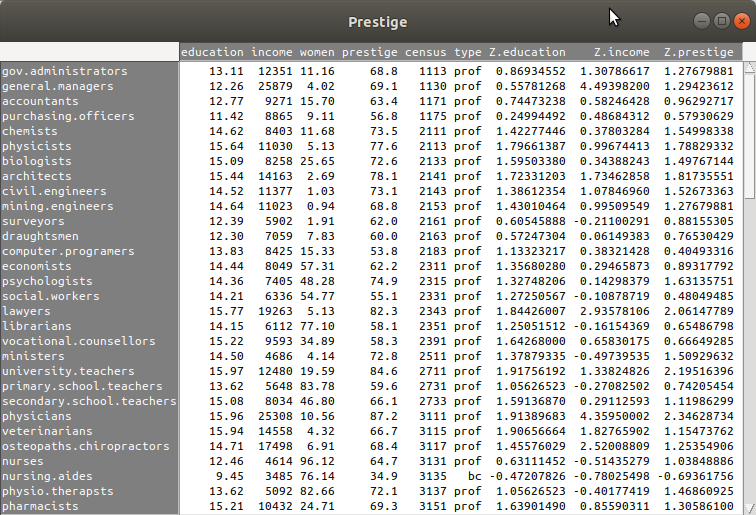
요인형 변수의 특징을 수리적으로 다루기 위해서 행렬(매트릭스) 형식으로 재구성하는 경우가 빈번하다. 변수 내부의 기준 수준을 정하거나, 개별 수준들의 특징(사례 갯수, 거리)을 기준으로 행렬을 만드는데 활용되는 선택사항들을 결정한다. Prestige 데이터셋에는 직업 유형을 뜻하는 type 이라는 요인형 변수가 있다. <요인 대비 설정하기> 기능은 요인형 변수에만 해당된다. 다음의 화면에서 선택할 수 있다.

?contrasts # stats 패키지의 contrasts 도움말 보기
utils::example(factor)
fff <- ff[, drop = TRUE] # reduce to 5 levels.
contrasts(fff) # treatment contrasts by default
contrasts(C(fff, sum))
contrasts(fff, contrasts = FALSE) # the 5x5 identity matrix
contrasts(fff) <- contr.sum(5); contrasts(fff) # set sum contrasts
contrasts(fff, 2) <- contr.sum(5); contrasts(fff) # set 2 contrasts
# supply 2 contrasts, compute 2 more to make full set of 4.
contrasts(fff) <- contr.sum(5)[, 1:2]; contrasts(fff)
## using sparse contrasts: % useful, once model.matrix() works with these :
ffs <- fff
contrasts(ffs) <- contr.sum(5, sparse = TRUE)[, 1:2]; contrasts(ffs)
stopifnot(all.equal(ffs, fff))
contrasts(ffs) <- contr.sum(5, sparse = TRUE); contrasts(ffs)'Data > Manage variables in active data set' 카테고리의 다른 글
| 9. Drop unused factor levels... (0) | 2022.02.10 |
|---|---|
| 8. Reorder factor levels... (0) | 2022.02.10 |
| 6. Convert character variables to factors... (0) | 2022.02.10 |
| 12. Delete variables from data set... (0) | 2020.03.21 |
| 11. Rename variables... (0) | 2020.03.21 |