통계 > 평균 > 이-요인 반복-측정 ANOVA/ANCOVA...
Statistics > Means > Two-factor repeated-measures ANOVA/ANCOVa...

데이터셋을 활성화시켰다면, '통계 > 평균 > 일-요인 반복-측정 ANOVA/ANCOVA' 메뉴 기능을 사용할 수 있다. carData 패키지의 OBrienKaiser 데이터셋을 이용하여 연습해보자.
먼저, OBrienKaiser 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 >
첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 OBrienKasier를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'OBrienKasier'로 바뀐다.
OBrienKaiser 데이터셋
carData 패키지에 있는 OBrienKaiser 데이터셋이다. carData 패키지는 Rcmdr 패키지가 호출될 때 자동으로 함께 호출되기 때문에 R Commander에서 carData 패키지에 포함된 데이터셋들을 자유롭게 호출할 수 있
rcmdr.kr
'통계 > 평균 > 이-요인 반복-측정 ANOVA/ANCOVA' 메뉴 기능을 선택하자. 아래와 같은 화면이 등장한다.

메뉴 창의 세부 항목을 아래와 같이 설정한다.


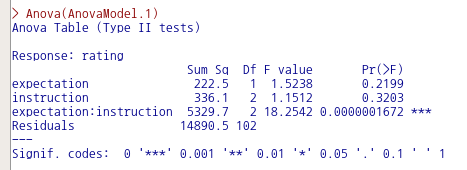
Anova(lm(cbind(pre.1, post.1, fup.1, pre.2, post.2, fup.2, pre.3, post.3, fup.3, pre.4, post.4, fup.4,
pre.5, post.5, fup.5) ~ gender*treatment, data=OBrienKaiser), idata=data.frame(Phase =
factor(rep(c('Pretest', 'Posttest', 'Followup'),5)), Hour = factor(rep(c('1', '2', '3', '4', '5'),
each=3))), idesign = ~Phase*Hour, test.statistic="Pillai")
repeatedMeasuresPlot(OBrienKaiser, within=c("pre.1", "post.1", "fup.1", "pre.2", "post.2", "fup.2",
"pre.3", "post.3", "fup.3", "pre.4", "post.4", "fup.4", "pre.5", "post.5", "fup.5"),
within.names=c("Phase", "Hour"), within.levels=list(Phase=c("Pretest", "Posttest", "Followup"),
Hour=c("1", "2", "3", "4", "5")), print.tables=FALSE, plot.means=TRUE, between.names=c("gender",
"treatment"), response.name="score")

?RepeatedMeasuresDialogs # RcmdrMisc 패키지의 RepeatedMeasuresDialogs 도움말 보기
?repeatedMeasuresPlot # RcmdrMisc 패키지의 repeatedMeasuresPlot 도움말 보기'Statistics > Means' 카테고리의 다른 글
| 6. One-factor repeated-measures ANOVA/ANCOVA... (0) | 2022.06.23 |
|---|---|
| 5. Multi-way ANOVA... (0) | 2022.03.13 |
| 4. One-way ANOVA... (0) | 2022.03.07 |
| 3. Paired t-test... (0) | 2022.03.07 |
| 2. Independent samples t-test... (0) | 2022.03.07 |