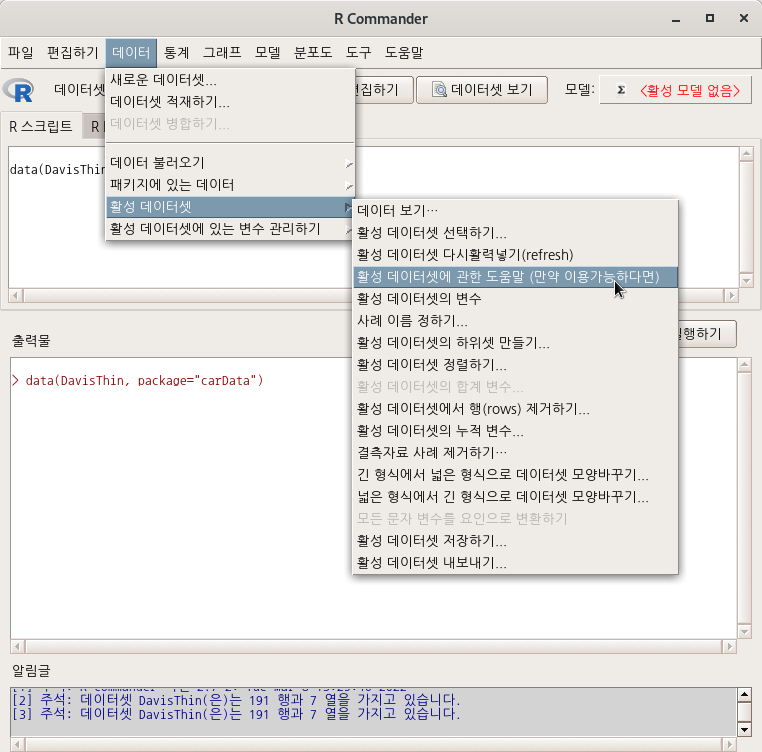
datasets::USArrests()

data(USArrests, package="datasets")R Commander 화면 상단에서 <데이터셋 보기> 버튼을 누르면 아래와 같은 내부 구성을 확인할 수 있다.

help("USArrests")| USArrests {datasets} | R Documentation |
Violent Crime Rates by US State
Description
This data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 US states in 1973. Also given is the percent of the population living in urban areas.
Usage
USArrestsFormat
A data frame with 50 observations on 4 variables.
| [,1] | Murder | numeric | Murder arrests (per 100,000) |
| [,2] | Assault | numeric | Assault arrests (per 100,000) |
| [,3] | UrbanPop | numeric | Percent urban population |
| [,4] | Rape | numeric | Rape arrests (per 100,000) |
Note
USArrests contains the data as in McNeil's monograph. For the UrbanPop percentages, a review of the table (No. 21) in the Statistical Abstracts 1975 reveals a transcription error for Maryland (and that McNeil used the same “round to even” rule that R's round() uses), as found by Daniel S Coven (Arizona).
See the example below on how to correct the error and improve accuracy for the ‘<n>.5’ percentages.
Source
World Almanac and Book of facts 1975. (Crime rates).
Statistical Abstracts of the United States 1975, p.20, (Urban rates), possibly available as https://books.google.ch/books?id=zl9qAAAAMAAJ&pg=PA20.
References
McNeil, D. R. (1977) Interactive Data Analysis. New York: Wiley.
See Also
The state data sets.
Examples
summary(USArrests)
require(graphics)
pairs(USArrests, panel = panel.smooth, main = "USArrests data")
## Difference between 'USArrests' and its correction
USArrests["Maryland", "UrbanPop"] # 67 -- the transcription error
UA.C <- USArrests
UA.C["Maryland", "UrbanPop"] <- 76.6
## also +/- 0.5 to restore the original <n>.5 percentages
s5u <- c("Colorado", "Florida", "Mississippi", "Wyoming")
s5d <- c("Nebraska", "Pennsylvania")
UA.C[s5u, "UrbanPop"] <- UA.C[s5u, "UrbanPop"] + 0.5
UA.C[s5d, "UrbanPop"] <- UA.C[s5d, "UrbanPop"] - 0.5
## ==> UA.C is now a *C*orrected version of USArrests
'Dataset_info > USArrests' 카테고리의 다른 글
| USArrests 데이터셋 예제 (0) | 2022.06.25 |
|---|