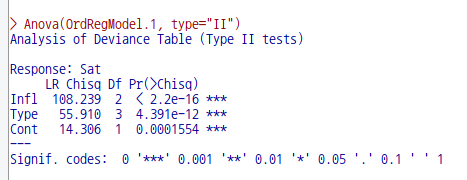
Sat는 거주자의 현 거주환경에 대한 만족도에 관한 변수로서, High > Medium > Low 라는 서열화된 요인을 갖고 있다. Sat를 반응변수로, 나머지를 설명변수의 후보군으로 모델을 구성하는 것이다. Freq 변수는 Sat, Infl, Type, Cont 등으로 구별되는 집단 구성원의 숫자를 뜻한다. 아래와 같이 모형을 만든다.
bwt 데이터셋은 분석 모형을 만드는데 간혹 예제로 사용되는데, birthwt에서 bwt가 만들어지는 과정이 R Commander 기본 사용자에게는 다소 어렵게 느껴질수 있겠다는 판단이다. 데이터셋 자체에 대한 이해의 어려움 때문에 분석 모형의 구성과 해석으로 나아가지 못하는 경우가 있어, bwt 데이터셋 설명을 하고자 한다.
bwt 데이터셋은 저체중아 출생의 원인을 찾고자 하는 문제의식을 담고 있다. low 변수는 출생당시 몸무게가 2.5kg 미만 여부를 담고 있으며, 반응변수가 된다. 나머지 변수들은 저체중아 출산에 영향을 끼치는가 여부인 설명변수들의 후보군이 되겠다.
통계 > 적합성 모델 > 선형 혼합 모델... Statistics > Fit models > Linear mixed model...
Linux 사례 (MX 21)
데이터셋을 활성화시키면, '통계 > 적합성 모델 > 선형 혼합 모델...' 메뉴 기능을 사용할 수 있다. lme4 패키지의 sleepstudy 데이터셋을 이용하여 연습해보자.
sleepstudy 데이터셋을 활성화 시키자. 먼저 lme4 패키지를 호출해야 한다. 그래야 포함된 데이터셋 목록을 확인할 수 있기 때문이다. '도구 > 패키지 적재하기...' 메뉴 기능을 통하여 lme4를 적재한다. 그리고 '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 lme4 패키지에 포함된 데이터셋들 중에서 sleepstudy를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'sleepstudy'로 바뀐다.
'데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하면 하위 선택 창으로 이동한다. 아래와 같이 lme4 패키지를 선택하고, sleepstudy 데이터셋을 찾아 선택한다.
Linux 사례 (MX 21)
sleepstudy 데이터셋이 활성화된다. R Commander 상단의 메뉴에서 < 활성 데이터셋 없음> 이 'sleepstudy'로 바뀐다.
Linux 사례 (MX 21)
summary(sleepstudy)
str(sleepstudy)
'통계 > 요약 > 활성 데이터셋' 메뉴 기능을 통해서 sleepstudy 데이터의 요약 정보를 살펴보자. str() 함수를 이용하여 sleepstudy 데이터셋의 내부 구조를 살펴보자.
Linux 사례 (MX 21)
데이터셋의 내부는 다음과 같다:
Linux 사례 (MX 21)
sleepstudy {lme4}
R Documentation
Reaction times in a sleep deprivation study
Description
The average reaction time per day for subjects in a sleep deprivation study. On day 0 the subjects had their normal amount of sleep. Starting that night they were restricted to 3 hours of sleep per night. The observations represent the average reaction time on a series of tests given each day to each subject.
Format
A data frame with 180 observations on the following 3 variables.
Reaction
Average reaction time (ms)
Days
Number of days of sleep deprivation
Subject
Subject number on which the observation was made.
Details
These data are from the study described in Belenky et al. (2003), for the sleep-deprived group and for the first 10 days of the study, up to the recovery period.
References
Gregory Belenky, Nancy J. Wesensten, David R. Thorne, Maria L. Thomas, Helen C. Sing, Daniel P. Redmond, Michael B. Russo and Thomas J. Balkin (2003) Patterns of performance degradation and restoration during sleep restriction and subsequent recovery: a sleep dose-response study. Journal of Sleep Research 12, 1–12.
Examples
str(sleepstudy)
require(lattice)
xyplot(Reaction ~ Days | Subject, sleepstudy, type = c("g","p","r"),
index = function(x,y) coef(lm(y ~ x))[1],
xlab = "Days of sleep deprivation",
ylab = "Average reaction time (ms)", aspect = "xy")
(fm1 <- lmer(Reaction ~ Days + (Days|Subject), sleepstudy))
(fm2 <- lmer(Reaction ~ Days + (1|Subject) + (0+Days|Subject), sleepstudy))
Statistics > Means > One-factor repeated-measures ANOVA/ANCOVA...
Linux 사례 (MX 21)
데이터셋을 활성화시켰다면, '통계 > 평균 > 일-요인 반복-측정 ANOVA/ANCOVA' 메뉴 기능을 사용할 수 있다. carData 패키지의 OBrienKaiser 데이터셋을 이용하여 연습해보자.
먼저, OBrienKaiser 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 >
첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 OBrienKasier를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'OBrienKasier'로 바뀐다.
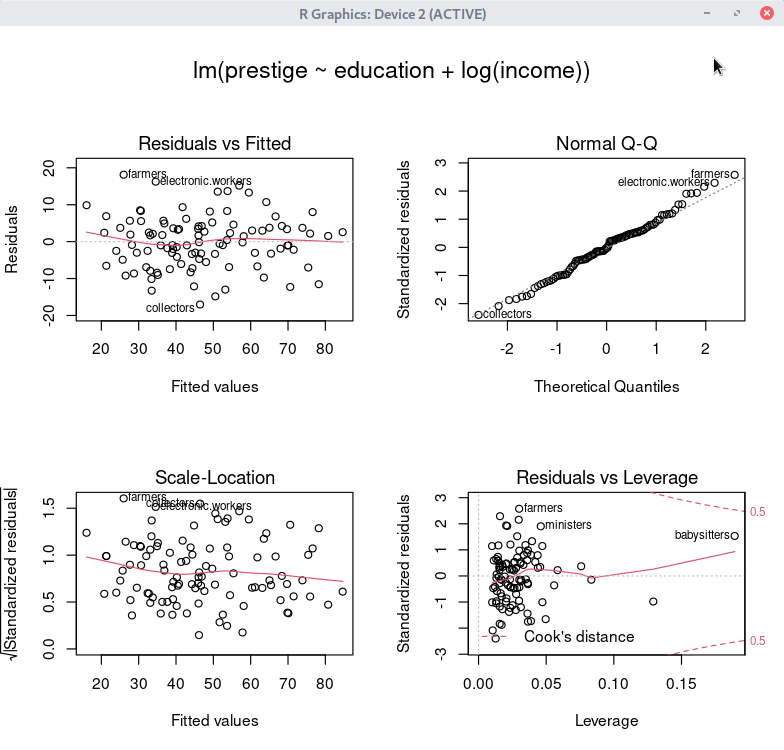
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > 기초 진단 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
모델 > 그래프 > Predictor 효과 그림... Models > Graphs > Predictor effect plots...
Linux 사례 (MX 21)
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > Predictor 효과 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > 영향력 색인 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.