Swiss Fertility and Socioeconomic Indicators (1888) Data
Description
Standardized fertility measure and socio-economic indicators for each of 47 French-speaking provinces of Switzerland at about 1888.
Usage
swiss
Format
A data frame with 47 observations on 6 variables, each of which is in percent, i.e., in [0, 100].
[,1]
Fertility
Ig, ‘common standardized fertility measure’
[,2]
Agriculture
% of males involved in agriculture as occupation
[,3]
Examination
% draftees receiving highest mark on army examination
[,4]
Education
% education beyond primary school for draftees.
[,5]
Catholic
% ‘catholic’ (as opposed to ‘protestant’).
[,6]
Infant.Mortality
live births who live less than 1 year.
All variables but ‘Fertility’ give proportions of the population.
Details
(paraphrasing Mosteller and Tukey):
Switzerland, in 1888, was entering a period known as the demographic transition; i.e., its fertility was beginning to fall from the high level typical of underdeveloped countries.
The data collected are for 47 French-speaking “provinces” at about 1888.
Here, all variables are scaled to [0, 100], where in the original, all but "Catholic" were scaled to [0, 1].
They state that variables Examination and Education are averages for 1887, 1888 and 1889.
Source
Project “16P5”, pages 549–551 in
Mosteller, F. and Tukey, J. W. (1977) Data Analysis and Regression: A Second Course in Statistics. Addison-Wesley, Reading Mass.
indicating their source as “Data used by permission of Franice van de Walle. Office of Population Research, Princeton University, 1976. Unpublished data assembled under NICHD contract number No 1-HD-O-2077.”
References
Becker, R. A., Chambers, J. M. and Wilks, A. R. (1988) The New S Language. Wadsworth & Brooks/Cole.
Examples
require(stats); require(graphics)
pairs(swiss, panel = panel.smooth, main = "swiss data",
col = 3 + (swiss$Catholic > 50))
summary(lm(Fertility ~ . , data = swiss))
하나의 데이터셋을 대상으로 가장 최적의 분석모형을 찾고자 할 때, 또는 보다 정교한 설명을 위하여 만들어진 모형들을 비교하고자 할 때 사용하는 기능이다.
예를 들어, carData에 포함된 Prestige 데이터셋을 이용하여 연습해보자. 직업의 사회적 권위(prestige)에 영향을 미치는 두 개의 독립변수(설명변수)를 교육기간(education)과 수입(income)이라고 가정하자. 그런데 education과 income의 선형적 관계에 대한 보다 깊은 고민을 한다고 생각해보자. education과 income이 서로 독립적인 선형관계로 prestige에 영향을 줄 수도 있고, 또 education과 income이 독립적인 영향을 줄 뿐 만 아니라, 서로 상호작용을 일으키면서 prestige에 영향을 추가 할 수 도 있다고 주장할 수 있다. 이러한 문제의식에서 아래와 같은 두개의 모형을 만들고 또 이 두개의 모형 중에서 어느것이 더 정교한지를 찾는다고 생각해보자.
참고로 연산자 +는 설명변수들의 독립적 선형관계를, *는 독립적 선형관계와 결합적 선형관계를 함께 계산하는데 사용한다.
LinearModel.1과 LinearModel.2라는 두 개의 모형을 만들고 두 개의 모델을 비교하는 방법이다. 모델 > 가설 검정 > 두 모델 비교하기...의 메뉴를 선택하면, 만들어 놓은 두 개의 모형을 비교하는 기능을 이용할 수 있다. 직관적으로 두개의 모형을 차례로 선택해보자. 그리고 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
R Commander 출력창에 다음과 같은 결과가 출력될 것이다. 출력 내용은 모델 1과 모델 2의 차이가 유의미하며 (Pr(>F)), 모델 2가 보다 설명력이 높다(Sum of sq > 0 또는 RSS < 0)는 뜻으로 해석할 수 있다.
R Commander를 설치하는 과정에서 의존패키지인 sem이 함께 설치된다. 안내가 나오면서 추가 설치를 하겠는가 물어보기도 한다. 위의 화면처럼, sem 패키지에 포함된 함수를 사용하는 <확인적 요인 분석...> 기능은 처음에는 비활성화되어 있다.
Linux 사례 (MX 21)
만약 Rcmdr 패키지가 호출될 때, sem 패키지가 자동으로 호출된다면, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...'에 sem 패키지가 carData, sandwich 처럼 메뉴창안의 패키지 목록에 포함되어 있어야 할 것이다. 하지만, 위의 화면에선 보이지 않는다. sem 패키지를 추가로 호출해주어야 한다는 뜻이다.
library(sem) #설치한 sem 패키지를 호출하기
Linux 사례 (MX 21)
sem 패키지가 호출되면, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...'기능에서 sem 패키지의 데이터셋을 선택할 수 있게 된다. 아래 화면을 살펴보라.
Linux 사례 (MX 21)
HS.data를 선택하자. HS.data 데이터셋이 활성화되면, 처음에 미활성화된 <확인적 요인 분석...> 메뉴가 활성화된다. <확인적 요인 분석...> 메뉴를 선택하면, 두개의 하위 창을 보게된다. 변수들을 선택하여 요인으로 묶는 <데이터> 창과, 연산을 통하여 획득하고자하는 통계지수(index) 목록의 <선택기능> 창이다.
위에 보이는 스크립트는 무엇을 나타내는가? 설명을 추가한다. 1. 선택된 HS.data는 여러개의 변수들을 포함하고 있다. 2. 최초의 연구목적에서 개념적으로 구성된 몇 몇 요인들이 있고, 이 요인들을 세부적으로 구성하는 것이 하위 변수들이다. 3. 변수들 몇 개씩을 묶어서 요인으로 재구성하는것, 연구적 의도에서 보면, 요인을 구성한다고 가정하여 세분화된 변수들의 사례적 값들이 실제로 요인을 구성하는지를 확인하는 작업이 <확인적 요인 분석>이다. 4. HS.data에 포함된 여러개의 변수들을 spatial, verbal, memory, math라는 네개의 개념화된 요인으로 변수들을 재그룹화 한것이다. 'spatial: cubes, flags, paper, visual' 'verbal: general, paragrap, sentence, wordc, wordm' 'memory: figurer, figurew, numberf, numberr, object, wordr' 'math: arithmet, deduct, numeric, problemr, series' 5. spatial, verbal, memory, math 라는 요인의 이름은 최초의 설계에서 등장하는 개념적 요인을 뜻하는 것이다. 편의상으로 factor.1, factor.2, factor.3, factor.4 등으로 이름을 붙여도 무방하다. 6. fit.indices라는 옵션에 AIC, BIC 두개의 통계지수가 포함되어 있는데, 이것은 <선택기능> 창의 기본설정이며, 원하는 지수를 추가로 선택할 수 있다. CFI, RMSEA 등이 선택될 수 있다.
데이터셋을 활성화시킨 다음, 그 데이터셋으로 모델을 만들었다고 생각하자. 예를 들어, carData 패키지의 Prestige 데이터셋으로 선형 모델을 만들었고, 그 모델을 LinearModel.1이라고 하자.
그럼, R Commander의 화면 메뉴 기능에서 '모델 > 관찰 통계를 데이터에 추가하기...' 기능이 활성화된다. 해당 메뉴 기능을 선택하면 아래와 같은 선택 창이 등장한다. 이 통계치들은 lm() 함수를 이용하여 모델을 생성하는 과정에서 함께 연산된 값들이며, 이 값들을 Prestige 데이터셋에 추가할 것인가를 질문받게 된다.
Linux 사례 (MX 21)
R Commander 화면에서 <데이터셋 보기>를 선택하면 관찰 통계치가 추가되어 있음을 아래와 같이 알 수 있다:
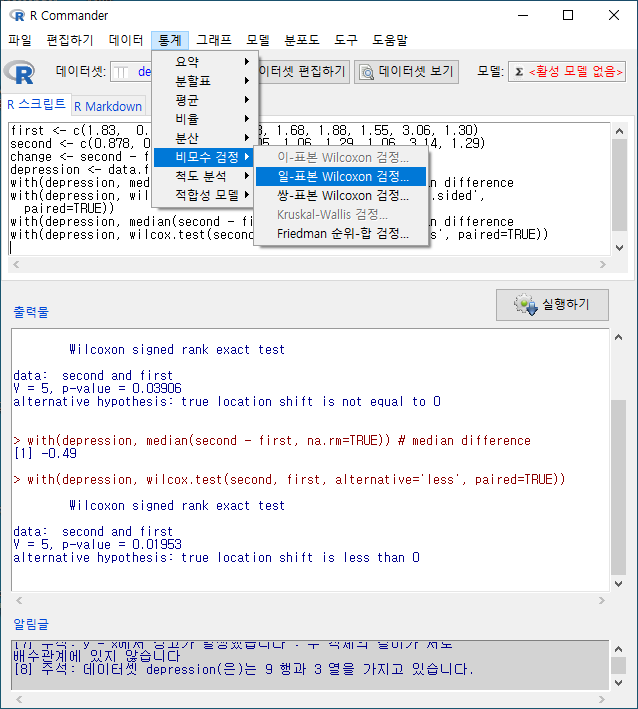
먼저 '통계 > 비모수 검정 > 쌍-표본 Wilcoxon 검정...'을 살펴보는 것을 추천한다. depression 이라는 데이터셋을 만들고, 변수 first, second, change를 만들었다. change는 second와 first의 차이에 관련 사례 값을 갖는다.
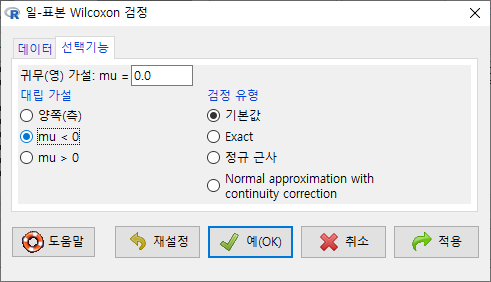
'통계 > 비모수 검정 > 일-표본 Wilcoxon 검정...'은 depression 데이터셋의 change 변수처럼 두 개 변수의 차이를 갖는 (또는 차이가 계산된) 변수를 기준값과 비교하여 차이 검정을 하는 기법이다. 때로는 특정 변수와 기준 값의 비교를 통하여 검정을 하기도 한다.
Windows 사례 (10 Pro)
데이터셋과 변수에 대한 의미적 판단이 깊은 경우 <대립 가설>의 선택을 다양하게 결정할 수 있다. 아래 화면에서 'mu < 0'은 change가 귀무(영) 가설, mu=0.0 일 때 depression 의 변화가 작아졌음을 확인하는 것으로 이해할 수 있다.
'통계 > 비모수 검정 > 이-표본 Wilcoxon 검정...' 기능을 이용하기 위해서 데이터셋을 선택하고, 정비해보자. datasets 패키지에 있는 airquality 데이터셋을 선택하고, 그 안에 있는 변수 Month 사례 값들 중에서 5월, 8월에 해당하는 5, 8을 선택한 하위 데이터셋을 만들고, airquality.sub라 이름 붙이자. 그리고, 5, 8을 요인화 시켜서, May, August라고 수준을 만들자.
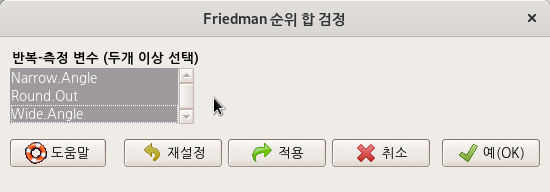
이 데이터셋을 만드는 이유는 friedman.test()라는 함수의 예제 연습에 포함되어있기 때문이다. RoundingTimes 데이터셋은 아래와 같은 내부 구성을 갖는다:
Linux 사례 (MX 21)
RoungdingTimes 라는 데이터셋을 만들고, 화면 맨 위에 있는 <Friedman 순위-합 검정...> 기능을 선택하면 추가적인 선택 메뉴 창으로 넘어간다. <Friedman 순위 합 검정> 창에서 <반복-측정 변수 (두개 이상 선택)>에서 세개의 변수를 모두 선택하고, 예(OK) 버튼을 누른다.