Statistics > Dimensional Analysis > Cluster Analysis > Add hierarchical clustering to data set...
Linux 사례 (MX 21)
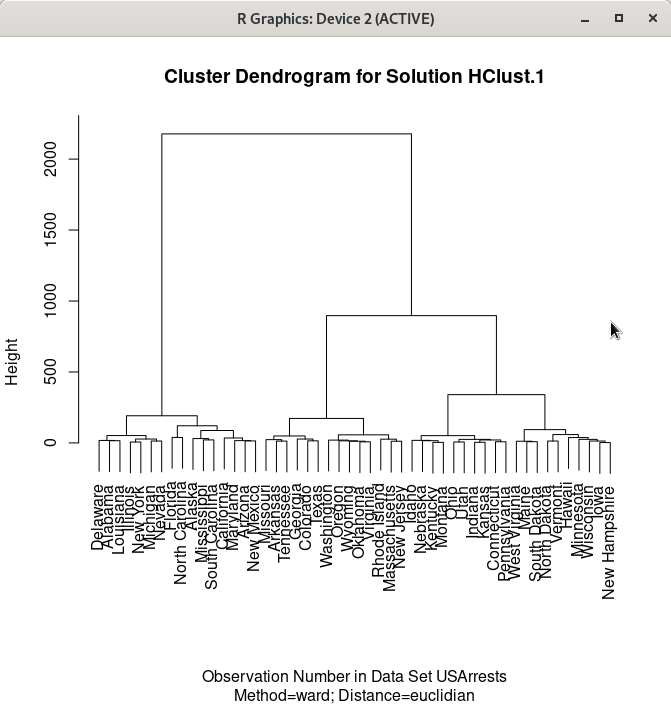
' 통계 > 차원 분석 > 군집 분석 > 위계 군집 분석...' 기능을 진행했다고 하자. 그 다음에 <위계군집화를 데이터 셋에 추가하기...>를 이용할 수 있다. <군집의 수:>를 3으로 변경하자. 그리고 예(OK) 버튼을 누르면, hclus.label라는 변수가 USArrests 데이터셋에 추가된다.
Linux 사례 (MX 21)
R Commander 상단에 있는 <데이터셋 보기> 버튼을 눌러보자. 아래와 같이 데이터셋의 내부 구성이 보일 것이다. hclus.label 변수가 추가되어 있음을 확인할 수 있다:
<선택기능> 창에서, 군집의 수를 3개, 초기값의 수를 5번으로, 최대 반복 횟수를 5회로 정해보자. 데이터셋에 추가될 변수 이름이 KMeans가 될 것이다. 아래 있는 선택사항에서 데이터셋에 군집 할당하기를 선택한다.
Windows 사례 (10 Pro)
위 화면에서 선택된 군집 행렬도(Bi-plot)이 아래와 같이 생산된다.
Windows 사례 (10 Pro)
USArrests 데이터셋에 변수 KMeans가 추가될 것이다. R Commander 상단에 있는 <데이터셋 보기> 버튼을 눌러보자. KMeans 변수는 요인형으로 1, 2, 3 이라는 세개의 군집을 표시한다.
Windows 사례 (10 Pro)
아래 화면은 다소 복잡해보일 것이다. 그러나 객체 .cluster가 만들어졌으며, 그 객체안에 있는 $size, $withinss, $tot.withinss, $betweenss 등의 정보를 차례를 보여준다고 생각하자. 그리고 biplot을 생산하고, USArrests 데이터셋에 KMeans라는 변수를 추가하는 것이다.
The “experimenters” were the actual subjects of the study. They collected ratings of the apparent success of people in pictures who were pre-selected for their average appearance of success. The experimenters were told prior to collecting data that particular subjects were either high or low in their tendency to rate appearance of success, and were instructed to get good data, scientific data, or were given no such instruction. Each experimenter collected ratings from 18 randomly assigned subjects. This version of the Adler data is taken from Erickson and Nosanchuk (1977). The data described in the original source, Adler (1973), have a more complex structure.
Usage
Adler
Format
This data frame contains the following columns:
instruction
a factor with levels:good, good data;none, no stress;scientific, scientific data.
expectation
a factor with levels:high, expect high ratings;low, expect low ratings.
rating
The average rating obtained.
Source
Erickson, B. H., and Nosanchuk, T. A. (1977)Understanding Data.McGraw-Hill Ryerson.
References
Adler, N. E. (1973) Impact of prior sets given experimenters and subjects on the experimenter expectancy effect.Sociometry36, 113–126.
<출력물> 창에서 스크립트 창 높이 (줄)과 출력물 창 높이 (줄) 을 조정할 수 있다. 자주 R Commander를 사용하다보면, 하나의 명령문을 실행한 다음 얻게되는 출력물을 출력창에서 한번에 보지 못할 때 불편함을 느낀다. 주로 통계적 모델의 요약 정보를 확인하고자 할 때 발생하는 현상이다.
아래 창은 스크립트 창 높이 (줄)을 7로, 출력물 창 높이 (줄)을 25로 변경한 사례이다.
R에 설치된 패키지 목록 창이 등장한다. 원하는 패키지(들)을 찾아서 선택하고 예(OK) 버튼을 누른다. 아래 화면은 vcd 패키지를 설치하는 사례이다.
Linux 사례 (MX 21)
library(vcd) # 원하는 패키지 적재하기
vcd 패키지를 적재(loading) 하는데, grid 패키지가 함께 탑재된 것을 출력창에서 확인할 수 있다. grid는 vcd 패키지가 제작되는데 의존한 패키지임을 의미한다. 어느 패키지가 메모리에 적재되는 과정은 그 패키지가 의존하는 패키지의 자동적인 적재를 동반한다.
두개 이상의 모델을 선택하고 그 안에 포함된 계수(coefficients)를 비교하는 기능이다.
carData 패키지에 있는 Prestige 데이터셋을 이용하여 income(연수입)과 education(교육연수)가 prestige(직업의 사회적 권위)에 미치는 영향에 대하여 분석한다고 가정하자. 최적의 모델을 찾기 위해서는 먼저 여러개의 모델을 만들어야 한다. 이 경우, 만들어진 여러개의 모델을 비교하는 과정에서 영향력이 통계적으로 지지되는 변수들을 찾고 또 그 계수에 대한 꼼꼼한 점검을 해야하는 경우가 많다.