R에서 외부 자료를 불러올 때 기본 포맷으로 .csv를 사용한다. 그러나, 현실에서 많은 사용자들은 그냥 엑셀포맷 .xlsx를 이용하는 경향이 짙다. R사용자가 자료를 .csv로 보내달라고 하면, 귀찮아할 것이다.
보내온 엑셀파일을 여는 방법이 있다. R Commander에서도 기능을 제공한다. 그러나, 솔직히 불편하게 되어있는 점을 인정하지 않을 수 없다. Rstudio에서 'Import Dataset...' 기능을 사용하면, 쉽게 엑셀 자료를 R로 불러올 수 있기 때문이다. 엑셀자료를 불러오는데 걸림돌은 엑셀 시트의 내용이 구조화되어 있지 않거나, 또는 구조화되어 있어도 빈 공간들이 많은 경우이다.
여러개의 엑셀 파일 또는 시트에서 데이터셋을 많이 불러오는 경우가 아니라면, 적어도 단일 데이터셋을 불러오는 경우라면, '편법'을 이용할 수 있다. 마이크로소프트 오피스 또는 엑셀 프로그램을 갖고 있는 경우, 또는 유사한 스프레드시트를 갖고 있는 경우는 원하는 부분을 블록화할 수 있고, 또 복사와 붙이기가 가능하다. 줄여말하면, 클립보드 기능을 사용하면 R로 엑셀에서 데이터셋을 불러올 수 있다. 매우 손쉽다.
1. 엑셀 시트에서 R로 불러오고 싶은 부분을 마우스를 이용하여 선택(drag)하고, 복사한 다음에
?faithful # datasets 패키지에 포함된 faithful 데이터셋 도움말 보기
faithful {datasets}
R Documentation
Old Faithful Geyser Data
Description
Waiting time between eruptions and the duration of the eruption for the Old Faithful geyser in Yellowstone National Park, Wyoming, USA.
Usage
faithful
Format
A data frame with 272 observations on 2 variables.
[,1]
eruptions
numeric
Eruption time in mins
[,2]
waiting
numeric
Waiting time to next eruption (in mins)
Details
A closer look at faithful$eruptions reveals that these are heavily rounded times originally in seconds, where multiples of 5 are more frequent than expected under non-human measurement. For a better version of the eruption times, see the example below.
There are many versions of this dataset around: Azzalini and Bowman (1990) use a more complete version.
Source
W. Härdle.
References
Härdle, W. (1991). Smoothing Techniques with Implementation in S. New York: Springer.
Azzalini, A. and Bowman, A. W. (1990). A look at some data on the Old Faithful geyser. Applied Statistics, 39, 357–365. doi: 10.2307/2347385.
See Also
geyser in package MASS for the Azzalini–Bowman version.
Examples
require(stats); require(graphics)
f.tit <- "faithful data: Eruptions of Old Faithful"
ne60 <- round(e60 <- 60 * faithful$eruptions)
all.equal(e60, ne60) # relative diff. ~ 1/10000
table(zapsmall(abs(e60 - ne60))) # 0, 0.02 or 0.04
faithful$better.eruptions <- ne60 / 60
te <- table(ne60)
te[te >= 4] # (too) many multiples of 5 !
plot(names(te), te, type = "h", main = f.tit, xlab = "Eruption time (sec)")
plot(faithful[, -3], main = f.tit,
xlab = "Eruption time (min)",
ylab = "Waiting time to next eruption (min)")
lines(lowess(faithful$eruptions, faithful$waiting, f = 2/3, iter = 3),
col = "red")
통계 > 적합성 모델 > 일반화 선형 혼합 모델... Statistics > Fit models > Generalized linear mixed model...
Linux 사례 (MX21)
'도구 > 패키지 적재하기...' 메뉴 기능을 이용하여 lme4 패키지를 찾아서 적재하자. lme4 패키지에는 일반화 선형 혼합 모델을 만들고 분석하는데 필요한 glmer()와 예제 데이터셋 cbpp가 포함되어 있다.
'데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 lme4 패키지에 있는 cbpp 데이터셋을 찾아서 선택하자. 그러면 R Commander의 상단에 있는 <활성 데이터셋 없음>이 'cbpp'로 활성화될 것이다. https://rcmdr.tistory.com/240
## response as a matrix
(m1 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd),
family = binomial, data = cbpp))
## response as a vector of probabilities and usage of argument "weights"
m1p <- glmer(incidence / size ~ period + (1 | herd), weights = size,
family = binomial, data = cbpp)
## Confirm that these are equivalent:
stopifnot(all.equal(fixef(m1), fixef(m1p), tolerance = 1e-5),
all.equal(ranef(m1), ranef(m1p), tolerance = 1e-5))
## GLMM with individual-level variability (accounting for overdispersion)
cbpp$obs <- 1:nrow(cbpp)
(m2 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd) + (1|obs),
family = binomial, data = cbpp))
Linux 사례 (MX 21)
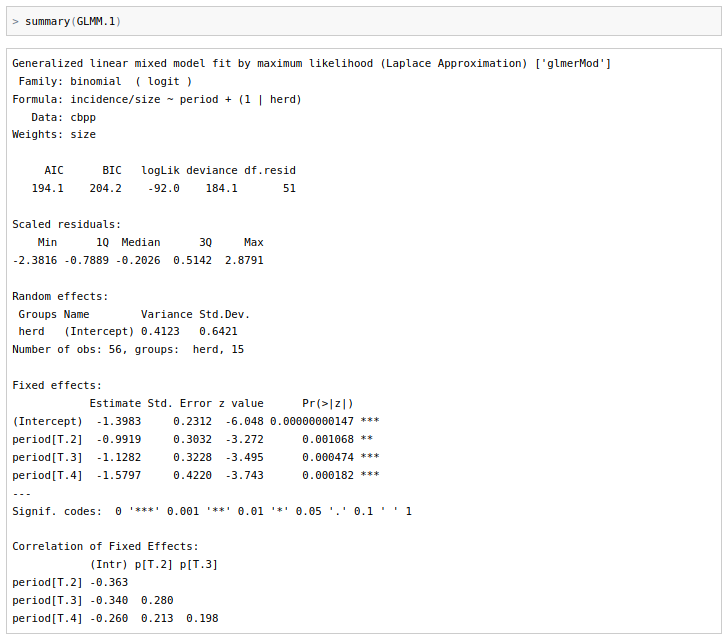
m1 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd),
family = binomial, data = cbpp)
summary(m1)
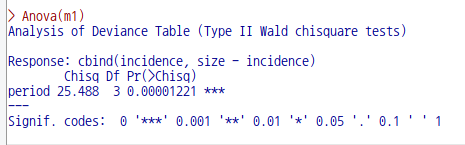
Anova(m1)
Linux 사례 (MX 21) - R MarkdownLinux 사례 (MX 21)
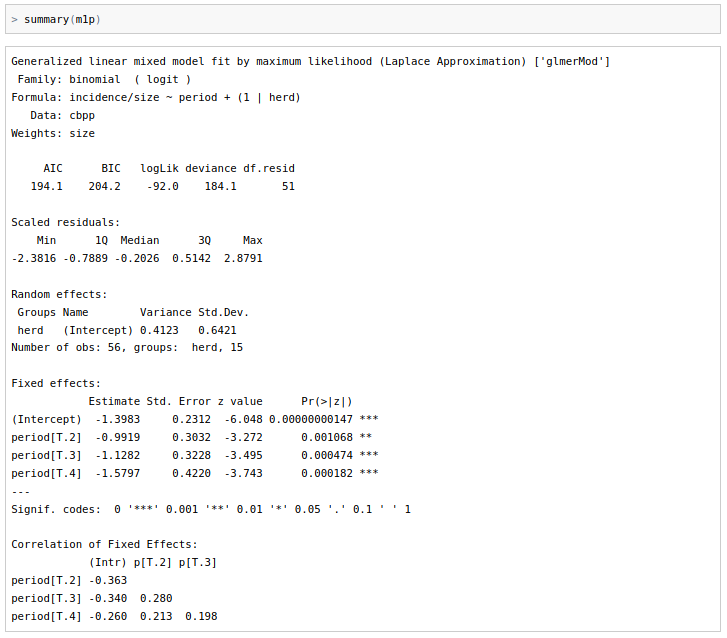
m1p <- glmer(incidence / size ~ period + (1 | herd), weights = size,
family = binomial, data = cbpp)
summary(m1p)
Anova(m1p)
Linux 사례 (MX 21) - R MarkdownLinux 사례 (MX 21)
## GLMM with individual-level variability (accounting for overdispersion)
cbpp$obs <- 1:nrow(cbpp)
m2 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd) + (1|obs),
family = binomial, data = cbpp)
summary(m2)
Anova(m2)
anova(m1, m2)
그리고 '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하면 하위 선택 창으로 이동한다. 아래와 같이 lme4 패키지를 선택하고, cbpp 데이터셋을 찾아서 선택한다.
Linux 사례 (MX 21)
cbpp 데이터셋이 활성화된다. R Commander 상단의 메뉴에서 < 활성 데이터셋 없음> 이 'cbpp'로 바뀐다.
summary(cbpp)
str(cbpp)
'통계 > 요약 > 활성 데이터셋' 메뉴 기능을 통해서 cbpp 데이터의 요약 정보를 살펴보자. str() 함수를 이용하여 cbpp 데이터셋의 내부 구조를 살펴보자.
Linux 사례 (MX 21)Linux 사례 (MX 21)
cbpp {lme4}
R Documentation
Contagious bovine pleuropneumonia
Description
Contagious bovine pleuropneumonia (CBPP) is a major disease of cattle in Africa, caused by a mycoplasma. This dataset describes the serological incidence of CBPP in zebu cattle during a follow-up survey implemented in 15 commercial herds located in the Boji district of Ethiopia. The goal of the survey was to study the within-herd spread of CBPP in newly infected herds. Blood samples were quarterly collected from all animals of these herds to determine their CBPP status. These data were used to compute the serological incidence of CBPP (new cases occurring during a given time period). Some data are missing (lost to follow-up).
Format
A data frame with 56 observations on the following 4 variables.
herd
A factor identifying the herd (1 to 15).
incidence
The number of new serological cases for a given herd and time period.
size
A numeric vector describing herd size at the beginning of a given time period.
period
A factor with levels 1 to 4.
Details
Serological status was determined using a competitive enzyme-linked immuno-sorbent assay (cELISA).
Source
Lesnoff, M., Laval, G., Bonnet, P., Abdicho, S., Workalemahu, A., Kifle, D., Peyraud, A., Lancelot, R., Thiaucourt, F. (2004) Within-herd spread of contagious bovine pleuropneumonia in Ethiopian highlands. Preventive Veterinary Medicine 64, 27–40.
Examples
## response as a matrix
(m1 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd),
family = binomial, data = cbpp))
## response as a vector of probabilities and usage of argument "weights"
m1p <- glmer(incidence / size ~ period + (1 | herd), weights = size,
family = binomial, data = cbpp)
## Confirm that these are equivalent:
stopifnot(all.equal(fixef(m1), fixef(m1p), tolerance = 1e-5),
all.equal(ranef(m1), ranef(m1p), tolerance = 1e-5))
## GLMM with individual-level variability (accounting for overdispersion)
cbpp$obs <- 1:nrow(cbpp)
(m2 <- glmer(cbind(incidence, size - incidence) ~ period + (1 | herd) + (1|obs),
family = binomial, data = cbpp))
'데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하면 하위 선택 창으로 이동한다. 아래와 같이 carData 패키지를 선택하고, Chile 데이터셋을 찾아서 선택한다.
Linux 사례 (MX 21)
Chile 데이터셋이 활성화된다. R Commander 상단의 메뉴에서 < 활성 데이터셋 없음> 이 'Chile'로 바뀐다.
summary(Chile)
str(Chile)
'통계 > 요약 > 활성 데이터셋' 메뉴 기능을 통해서 Chile 데이터의 요약 정보를 살펴보자. str() 함수를 이용하여 Chile 데이터셋의 내부 구조를 살펴보자.
Linux 사례 (MX 21)
데이터셋의 내부는 다음과 같다:
Linux 사례 (MX 21)
Chile {carData}
R Documentation
Voting Intentions in the 1988 Chilean Plebiscite
Description
The Chile data frame has 2700 rows and 8 columns. The data are from a national survey conducted in April and May of 1988 by FLACSO/Chile. There are some missing data.
Usage
Chile
Format
This data frame contains the following columns:
region
A factor with levels: C, Central; M, Metropolitan Santiago area; N, North; S, South; SA, city of Santiago.
population
Population size of respondent's community.
sex
A factor with levels: F, female; M, male.
age
in years.
education
A factor with levels (note: out of order): P, Primary; PS, Post-secondary; S, Secondary.
income
Monthly income, in Pesos.
statusquo
Scale of support for the status-quo.
vote
a factor with levels: A, will abstain; N, will vote no (against Pinochet); U, undecided; Y, will vote yes (for Pinochet).
Source
Personal communication from FLACSO/Chile.
References
Fox, J. (2016) Applied Regression Analysis and Generalized Linear Models, Third Edition. Sage.
Fox, J. and Weisberg, S. (2019) An R Companion to Applied Regression, Third Edition, Sage.
요인형 변수를 두개 이상 가지고 있는 데이터셋이 활성화되어 있다면, '통계 > 비율 > 이-표본 비율 검정..' 메뉴 기능을 이용할 수 있다. carData 패키지에 있는 Chile 데이터셋을 활용해서 연습해보자. 먼저, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 Chile 데이터셋을 활성화시키자. R Commander 상단에 'Chile'라는 데이터셋이 활성화되었는지 확인하자.
Statistics > Means > Two-factor repeated-measures ANOVA/ANCOVa...
Linux 사례 (MX 21)
데이터셋을 활성화시켰다면, '통계 > 평균 > 일-요인 반복-측정 ANOVA/ANCOVA' 메뉴 기능을 사용할 수 있다. carData 패키지의 OBrienKaiser 데이터셋을 이용하여 연습해보자.
먼저, OBrienKaiser 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 >
첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 OBrienKasier를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'OBrienKasier'로 바뀐다.