MASS::housing()
library(MASS, pos=16)
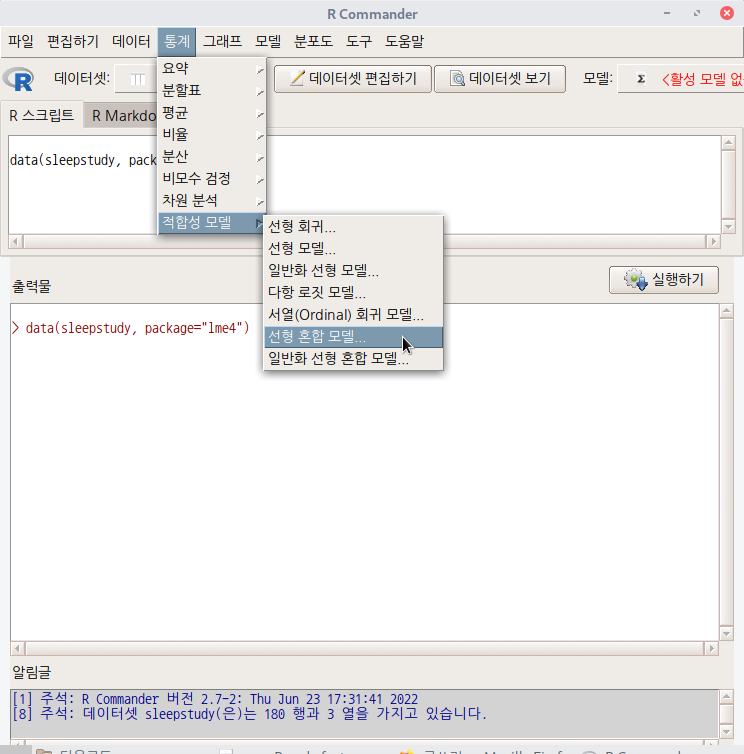
data(housing, package="MASS")'도구 > 패키지 적재하기...' 메뉴 기능을 선택하고, MASS 패키지를 찾아서 선택한다.
그리고나서, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하면 하위 선택 창으로 이동한다. 아래와 같이 MASS 패키지를 선택하고, housing 데이터셋을 찾아 선택한다.

housing 데이터셋이 활성화된다. R Commander 상단의 메뉴에서 < 활성 데이터셋 없음> 이 'housing'로 바뀐다.

summary(housing)
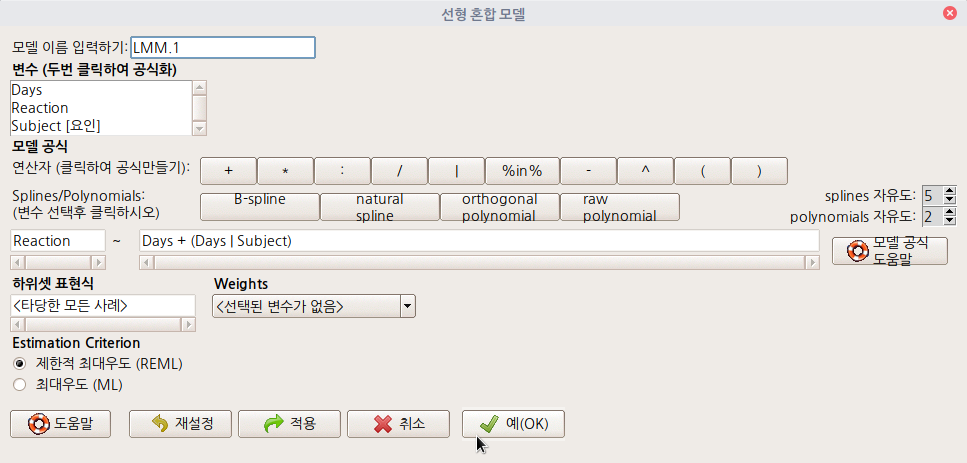
str(housing)'통계 > 요약 > 활성 데이터셋' 메뉴 기능을 선택하여 housing 데이터셋의 요약 정보를 살펴보자. 아울러 입력창에 str(housing)을 입력하고 <실행하기> 버튼을 누르자.

데이터셋의 내부는 다음과 같다:

| housing {MASS} | R Documentation |
Frequency Table from a Copenhagen Housing Conditions Survey
Description
The housing data frame has 72 rows and 5 variables.
Usage
housing
Format
Sat
Satisfaction of householders with their present housing circumstances, (High, Medium or Low, ordered factor).
Infl
Perceived degree of influence householders have on the management of the property (High, Medium, Low).
Type
Type of rental accommodation, (Tower, Atrium, Apartment, Terrace).
Cont
Contact residents are afforded with other residents, (Low, High).
Freq
Frequencies: the numbers of residents in each class.
Source
Madsen, M. (1976) Statistical analysis of multiple contingency tables. Two examples. Scand. J. Statist. 3, 97–106.
Cox, D. R. and Snell, E. J. (1984) Applied Statistics, Principles and Examples. Chapman & Hall.
References
Venables, W. N. and Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth edition. Springer.
Examples
options(contrasts = c("contr.treatment", "contr.poly"))
# Surrogate Poisson models
house.glm0 <- glm(Freq ~ Infl*Type*Cont + Sat, family = poisson,
data = housing)
## IGNORE_RDIFF_BEGIN
summary(house.glm0, cor = FALSE)
## IGNORE_RDIFF_END
addterm(house.glm0, ~. + Sat:(Infl+Type+Cont), test = "Chisq")
house.glm1 <- update(house.glm0, . ~ . + Sat*(Infl+Type+Cont))
summary(house.glm1, cor = FALSE)
1 - pchisq(deviance(house.glm1), house.glm1$df.residual)
dropterm(house.glm1, test = "Chisq")
addterm(house.glm1, ~. + Sat:(Infl+Type+Cont)^2, test = "Chisq")
hnames <- lapply(housing[, -5], levels) # omit Freq
newData <- expand.grid(hnames)
newData$Sat <- ordered(newData$Sat)
house.pm <- predict(house.glm1, newData,
type = "response") # poisson means
house.pm <- matrix(house.pm, ncol = 3, byrow = TRUE,
dimnames = list(NULL, hnames[[1]]))
house.pr <- house.pm/drop(house.pm %*% rep(1, 3))
cbind(expand.grid(hnames[-1]), round(house.pr, 2))
# Iterative proportional scaling
loglm(Freq ~ Infl*Type*Cont + Sat*(Infl+Type+Cont), data = housing)
# multinomial model
library(nnet)
(house.mult<- multinom(Sat ~ Infl + Type + Cont, weights = Freq,
data = housing))
house.mult2 <- multinom(Sat ~ Infl*Type*Cont, weights = Freq,
data = housing)
anova(house.mult, house.mult2)
house.pm <- predict(house.mult, expand.grid(hnames[-1]), type = "probs")
cbind(expand.grid(hnames[-1]), round(house.pm, 2))
# proportional odds model
house.cpr <- apply(house.pr, 1, cumsum)
logit <- function(x) log(x/(1-x))
house.ld <- logit(house.cpr[2, ]) - logit(house.cpr[1, ])
(ratio <- sort(drop(house.ld)))
mean(ratio)
(house.plr <- polr(Sat ~ Infl + Type + Cont,
data = housing, weights = Freq))
house.pr1 <- predict(house.plr, expand.grid(hnames[-1]), type = "probs")
cbind(expand.grid(hnames[-1]), round(house.pr1, 2))
Fr <- matrix(housing$Freq, ncol = 3, byrow = TRUE)
2*sum(Fr*log(house.pr/house.pr1))
house.plr2 <- stepAIC(house.plr, ~.^2)
house.plr2$anova
'Dataset_info > housing' 카테고리의 다른 글
| housing 데이터셋 예제 (0) | 2022.06.25 |
|---|