데이터 > 활성 데이터셋의 변수 관리하기 > 사용하지 않은 요인 수준 누락시키기...
Data > Manage variables in active data set > Drop unused factor levels...

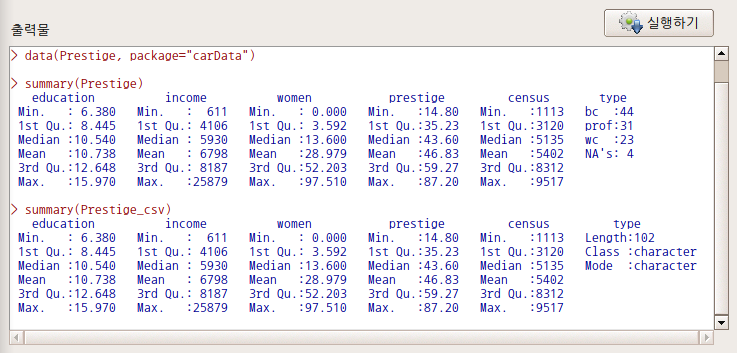
carData 패키지에 있는 Prestige 데이터셋에는 type 이라는 요인형 변수가 있다. bc, prof, wc 라는 수준을 갖고 있다. blue collar, professional, white collar를 뜻한다. 블루칼라와 화이트칼라 그룹의 수입(연봉), 학력(교육연수), 직업권위를 뜻하는 income, education, prestige 라는 변수의 정보를 비교하고자 한다. 먼저 prof 수준을 데이터셋에서 제거해야 할 것이다.

참고로, <하위셋 표현식>을 보다 꼼꼼히 살펴보라
Prestige.sub1 <- subset(Prestige, subset=type !="prof") [O]
Prestige.sub1 <- subset(Prestige, subset=type=!prof) [X]
Prestige.sub1 <- subset(Prestige, subset=type=!"prof") [X]
아래 출력창에서 Prestige 데이터셋의 type, Prestige.sub1 데이터셋의 type 요약 정보를 비교해보라. Prestige 데이터셋의 type 변수에는 prof 수준을 가진 31개의 사례가 사라졌지만, prof 수준은 아직 남아있다.

Prestige.sub1의 type 변수에서 사용되지 않는 수준인, 다른말로 사례를 갖고 있는 않는 수준인 prof를 제거하자. 그래서 bc, wc 두개의 수준을 비교하는 정보를 만들고, 분석한다고 하자. <수준을 누락시킬 요인 (하나 이상 선택)>에서 type을 선택하고, 예(OK) 버튼을 누른다.

그리고 아래 화면에서 OK 버튼을 누른다.

Prestige.sub1 <- within(Prestige.sub1, {
type <- droplevels(type)
})출력창에서 사용하지않는 요인 수준이 있는 변수정보와 누락시킨 이후의 변수정보를 찾아 비교해보라. type변수에 사례가 없는 prof 수준이 제거된 후 bc와 wc 두개 요인만 보일 것이다.

?droplevels # base 패키지의 droplevels 도움말 보기
aq <- transform(airquality, Month = factor(Month, labels = month.abb[5:9]))
aq <- subset(aq, Month != "Jul")
table( aq $Month)
table(droplevels(aq)$Month)'Data > Manage variables in active data set' 카테고리의 다른 글
| 10. Define contrasts for a factor... (0) | 2022.02.10 |
|---|---|
| 8. Reorder factor levels... (0) | 2022.02.10 |
| 6. Convert character variables to factors... (0) | 2022.02.10 |
| 12. Delete variables from data set... (0) | 2020.03.21 |
| 11. Rename variables... (0) | 2020.03.21 |