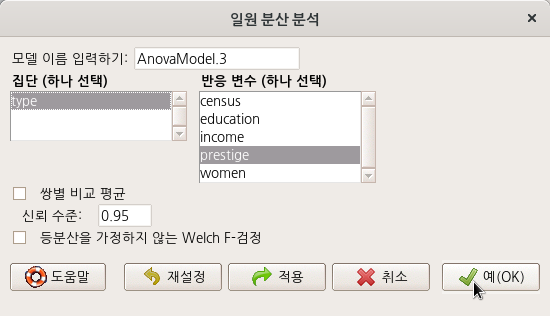
carData 패키지에서 제공하는 Prestige 데이터셋을 활성화 시키자. Prestige 데이터셋에는 type 이라는 세개의 수준을 가진 요인형 변수가 있다. 그 수준 이름은 bc, prof, wc 이다. 직업유형(type)별로 사회적인 권위가 다른지를 확인하는 문제의식이 있다고 하자. 집단별(직업유형, type)로 직업의 사회적 권위(prestige)에 대한 분산의 차이가 있는지를 통계적으로 살펴본다.
Linux 사례 (MX 21)
Tapply(prestige ~ type, var, na.action=na.omit, data=Prestige) # variances by group
bartlett.test(prestige ~ type, data=Prestige)
추가로 carData 패키지의 Prestige 데이터셋을 이용하여 일원 분산 분석을 연습해보자. Prestige 데이터셋에는 type 이라는 요인형 변수가 있다. 그러나 앞서 연습한 sleep 데이터셋의 group 변수처럼 요인 수준이 두개가 아니라 요인의 수준이 셋이다. 직업의 사회적 권위에 대한 직업 유형별 (bc, prof, wc) 평균의 차이가 있는가를 점검한다.
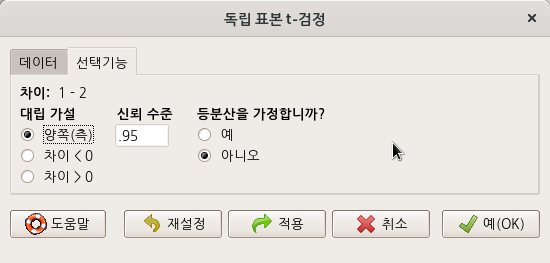
<이-분산 F-검정> 메뉴창에서 요인형 변수 group을 <집단 (하나 선택)>에, 수치형 변수 extra를 <반응 변수 (하나 선택)>으로 결정하자. Two variances F-test (이-분산 F-검정)은 두 개의 집단 비교로 반응 변수의 분산을 점검하는 기법이다.
Linux 사례 (MX 21)
Tapply(extra ~ group, var, na.action=na.omit, data=sleep) # variances by group
var.test(extra ~ group, alternative='two.sided', conf.level=.95, data=sleep)
alternative 이후 선택 사항들은 기본 선택을 사용하였다. 변화를 준 것은 없다. 따라서 아래의 명령문과 같은 의미이기도 하다.
var.test(extra ~ group, data=sleep)
sleep 데이터셋에 있는 extra 변수의 요인 수준 (group1, group2)별 분산은 차이가 있다고 통계적으로 말하기 어렵다는 결론을 얻는다. 줄여서 거칠게 말하면, 두 분산의 차이가 없다고 할 수 있다.
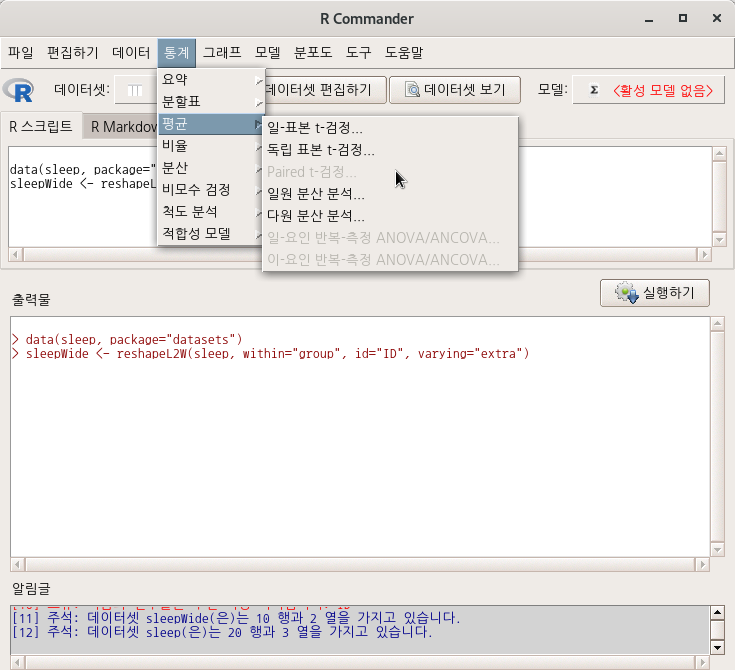
datasets 패키지에 포함된 sleep 데이터셋에는 extra라는 수치형 변수가 포함되어 있다. 수치형 변수가 하나만 있는 경우는 Paired t-검정을 사용할 수 없다. 10명이 각각 2개의 약을 복용한 후 group1, group2라는 집단 안에서 수면 시간의 변화를 측정한 데이터셋이다. reshape(), reshapeL2W() 등의 함수를 사용하여 extra라는 수치형 변수를 group1 , group2 별로 두개의 수치형 변수로 변환시켜야 한다. 변환이 되면 <Statistics : Means : Paired t-test> 기능이 활성화된다.
?t.test # stats 패키지의 t.test 도움말 보기
require(graphics)
t.test(1:10, y = c(7:20)) # P = .00001855
t.test(1:10, y = c(7:20, 200)) # P = .1245 -- NOT significant anymore
## Classical example: Student's sleep data
plot(extra ~ group, data = sleep)
## Traditional interface
with(sleep, t.test(extra[group == 1], extra[group == 2]))
## Formula interface
t.test(extra ~ group, data = sleep)
## Formula interface to one-sample test
t.test(extra ~ 1, data = sleep)
## Formula interface to paired test
## The sleep data are actually paired, so could have been in wide format:
sleep2 <- reshape(sleep, direction = "wide",
idvar = "ID", timevar = "group")
t.test(Pair(extra.1, extra.2) ~ 1, data = sleep2)
?t.test # stats 패키지의 t.test 도움말 보기
require(graphics)
t.test(1:10, y = c(7:20)) # P = .00001855
t.test(1:10, y = c(7:20, 200)) # P = .1245 -- NOT significant anymore
## Classical example: Student's sleep data
plot(extra ~ group, data = sleep)
## Traditional interface
with(sleep, t.test(extra[group == 1], extra[group == 2]))
## Formula interface
t.test(extra ~ group, data = sleep)
## Formula interface to one-sample test
t.test(extra ~ 1, data = sleep)
## Formula interface to paired test
## The sleep data are actually paired, so could have been in wide format:
sleep2 <- reshape(sleep, direction = "wide",
idvar = "ID", timevar = "group")
t.test(Pair(extra.1, extra.2) ~ 1, data = sleep2)
<대립 가설>에 관련된 선택사항에 변화를 주지 않았다. 아래 명령문과 같은 결과를 얻는다.
t.test(extra ~ 1, data = sleep)
Linux 사례 (MX 21)
?t.test # stats 패키지의 t.test 도움말 보기
require(graphics)
t.test(1:10, y = c(7:20)) # P = .00001855
t.test(1:10, y = c(7:20, 200)) # P = .1245 -- NOT significant anymore
## Classical example: Student's sleep data
plot(extra ~ group, data = sleep)
## Traditional interface
with(sleep, t.test(extra[group == 1], extra[group == 2]))
## Formula interface
t.test(extra ~ group, data = sleep)
## Formula interface to one-sample test
t.test(extra ~ 1, data = sleep)
## Formula interface to paired test
## The sleep data are actually paired, so could have been in wide format:
sleep2 <- reshape(sleep, direction = "wide",
idvar = "ID", timevar = "group")
t.test(Pair(extra.1, extra.2) ~ 1, data = sleep2)
통계 > 적합성 모델 > 선형 모델... Statistics > Fit models > Linear model...
Linux 사례 (MX 21)
아래와 같은 <선형 모델> 선택 창에서 변수들을 선택할 수 있다. ‘통계 > 적합성 모델 >선형 회귀...‘기능의 <선형 회귀...>창과 달리 선택할 수 있는 변수에 'type [요인]'이 추가되어 있다.
carData 패키지에서 제공되는 Prestige 데이터셋에는 요인형 변수 type이 포함되어 있다. <선형 모델> 기능에는 요인형 변수를 함께 넣어서 계산할 수 있고, 표본을 모집단 크기에 비율적으로 맞추고자 사례 값에 가중치를 넣어서 계산하는 <Weights> 선택 기능이 있다. 그리고 변수를 선택하는 것을 뛰어넘어 변수들 사이의 관계성을 수식화 할 수 있는 <모델 공식> 기능이 포함되어 있다.
Linux 사례 (MX 21)
아래 <선형 모델> 창은 위의 모델 구성식과는 다른 방식을 제안한다. 직업의 사회적 권위 (prestige)에 대한 education + income + women + type 의 영향력을 계산하는 것이 아니라, education + log(income)의 결과와 type의 관계가 prestige 변수에 미치는 영향력을 계산하는 식이다.
carData 패키지에서 제공하는 Prestige 데이터셋을 불러와서 활성화시키자. 그러면, 위의 화면처럼 <선형 회귀...> 기능이 활성화될 것이다. 이 기능을 선택하면 아래와 같이 Prestige 데이터셋의 변수 목록이 등장하며, 회귀분석을 위한 구조적 설계를 시작한다.
교육연수(education)와 연소득(income)이 직업의 사회적권위(prestige)에 영향을 미치는가? 어떤 영향을 미치는가? 등의 문제의식을 통계적으로 점검한다고 해보자. 교육연수와 연소득은 설명 변수일 것이며, 직업의 사회적 권위는 이 두개의 설명 변수로부터 영향을 받는 반응 변수가 될 것이다. 한편, <모델 이름 입력하기:>에는 RegModel.1이 자동적으로 추천된다. 여러 개의 모델을 만들어 점검하는 경우, 지속적으로 일련번호가 추가된다. 분석가가 자유롭게 모델 이름을 정할 수 있다.
Linux 사례 (MX 21)
예(OK) 버튼을 누르면, R Commander 화면 상단에 있는 <모델:>옆에 파란색으로 RegModel.1이 등장한다.
그래프 > 그래프를 파일로 저장하기 > 3차원 RGL 그래프... Graphs > Save graph to file > 3D RGL graph...
Linux 사례 (MX 21) Linux 사례 (MX 21)
위의 그래프는 carData 패키지에서 제공하는 Prestige 데이터셋을 활용하여 만들었다. 3차원 그래프가 만들어졌다면, <3차원 RGL 그래프...> 기능이 활성화된다. 그리고 그 기능을 마우스로 선택하면 아래와 같은 경로, 파일이름, 형식을 추천하는 메뉴 창이 등장한다.