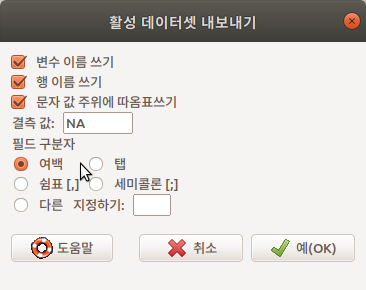
데이터 > 활성 데이터셋의 변수 관리하기 > 수치 변수 구간만들기...
Data > Manage variables in active data set > Bin a numeric variable...

수치 변수를 촘촘히 연결된 연속형 변수라고 생각해보자. 선 그래프로 시각화 할 수 있을 것이다. 연속적인 값들을 구간으로 나누어 쪼개어 배치하는 기법이 필요할 수 있다. 흔히 연령을 연령대로 만드는 작업이 이것에 속한다.
구간을 만드는 작업창에는 몇 몇 검토 사항의 조건들을 묻는 내용이 있다.
1. 몇 개의 구간을 만들 것인가?
2. 구간 수준의 이름을 어떻게 정할 것인가?
3. 구간화 작업을 넓이로, 계산치로, 군집화로 할 것인가?
몇 개의 구간을 만들 것인가라는 질문에 답을 결정하려면, 아마도 이 수치형 변수의 요약적 특징을 미리 알고 있어야 할 것이다. 그리고, 구간화 작업에서 동일-넓이 구간이 기본 선택사항인데, 다른 선택을 하려면, 데이터에 대한 이해와 높은 분석적 통찰력이 요구될 것이다.
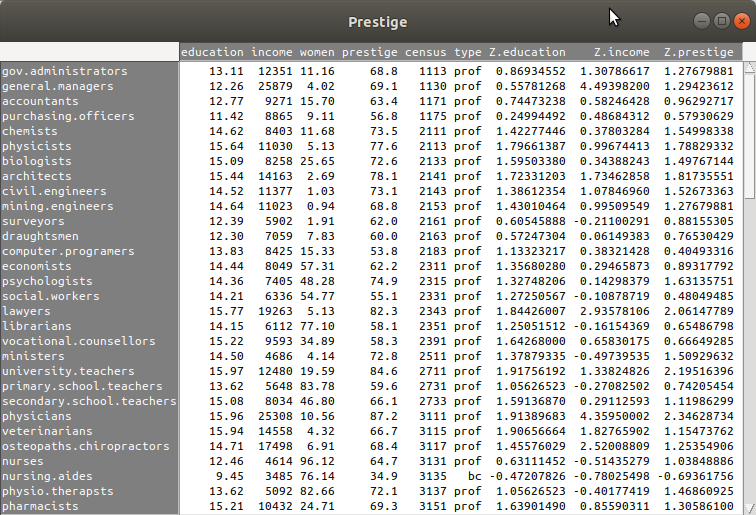
carData 패키지에 있는 Prestige 데이터셋의 수입(연봉)을 뜻하는 income 변수를 구간으로 쪼개자. income 변수는 수치형 변수이다. 102개의 income 변수의 사례 요약은 다음과 같다:

income.bin1, income.bin2, income.bin3 등 세개의 income 변수 구간화 작업을 하자. 구간의 수는 3개로, 수준 이름은 lower, middle, upper로 정하자. 구간화 기법은 bin1은 동일-넓이 구간, bin2는 동일-계산치 구간, bin3는 Natural breaks(K-평균 군집화에서)을 각각 선택하자.


아래 출력창에서 각각의 구간화 인자 method와 세 변수의 요인 갯수를 살펴보라.

<데이터셋 보기> 버튼을 눌러 Prestige 데이터셋에서 income.bin1, income.bin2, income.bin3의 요인들을 살펴보라.

?binVariable # RcmdrMisc 패키지에서 binVariable 도움말 보기
summary(binVariable(rnorm(100), method="prop", labels=letters[1:4]))'Data > Manage variables in active data set' 카테고리의 다른 글
| 12. Delete variables from data set... (0) | 2020.03.21 |
|---|---|
| 11. Rename variables... (0) | 2020.03.21 |
| 5. Convert numeric variable to factor... (0) | 2020.03.18 |
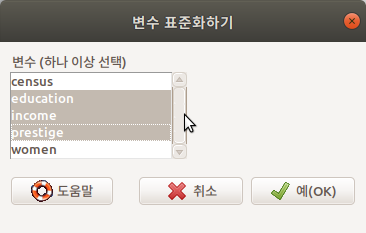
| 4. Standardize variables... (0) | 2019.09.08 |
| 3. Add observation number to data set (0) | 2019.09.08 |