모델 > 관찰 통계를 데이터에 추가하기...
Models > Add observation statistics to data...

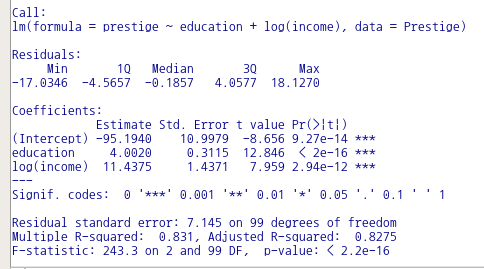
데이터셋을 활성화시킨 다음, 그 데이터셋으로 모델을 만들었다고 생각하자. 예를 들어, carData 패키지의 Prestige 데이터셋으로 선형 모델을 만들었고, 그 모델을 LinearModel.1이라고 하자.
그럼, R Commander의 화면 메뉴 기능에서 '모델 > 관찰 통계를 데이터에 추가하기...' 기능이 활성화된다. 해당 메뉴 기능을 선택하면 아래와 같은 선택 창이 등장한다. 이 통계치들은 lm() 함수를 이용하여 모델을 생성하는 과정에서 함께 연산된 값들이며, 이 값들을 Prestige 데이터셋에 추가할 것인가를 질문받게 된다.

R Commander 화면에서 <데이터셋 보기>를 선택하면 관찰 통계치가 추가되어 있음을 아래와 같이 알 수 있다:

data(Prestige) # 데이터셋 불러오기
summary(LinearModel.1) # 모델 만든후 요약정보 보기
Prestige<- within(Prestige, {
fitted.LinearModel.1 <- fitted(LinearModel.1)
residuals.LinearModel.1 <- residuals(LinearModel.1)
rstudent.LinearModel.1 <- rstudent(LinearModel.1)
hatvalues.LinearModel.1 <- hatvalues(LinearModel.1)
cooks.distance.LinearModel.1 <- cooks.distance(LinearModel.1)
obsNumber <- 1:nrow(Prestige)
})