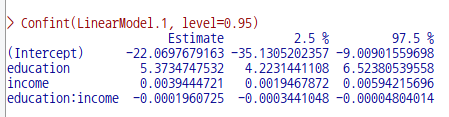
'모델 > 부트스트랩 신뢰 구간...'메뉴 바로 위에 '모델 > 신뢰 구간...'메뉴 기능이 있다. 이 때 쓰이는 함수가 위의 출력물 결과창에서 보는 것처럼 Confint()이다. '부트스트랩 신뢰 구간...' 기능은 신뢰 구간을 구하는 Confint()함수에 LinearModel.1을 바로 객체로서 사용하는 것이 아니라, 위에 화면 상단에서 보듯이 .bs.samples를 객체로 사용한다. .bs.samples라는 객체는 Boot()를 사용하여 만들어진다. Boot()는 LinearModel.1 모형을 활용하여 필요한 정보를 추출하는데, 1번의 분석이 아닌 'R=999' 처럼 999회 반복 추출을 한다. 이 과정은 과거 컴퓨터의 성능이 낮을 때는 매우 많은 시간을 요구하는 기능이었으나, 컴퓨터 성능의 향상으로 시간이 많이 단축되었다.
그렇다면, 왜 'R=999'처럼 반복 추출을 통한 분석을 999회 실시하여 방대한 분석 자료를 만들까. 자료는 일반적으로 제한된 사례수에 의하여, 또는 이론적인 분포를 적용하기 어려운 불규칙한 특징을 갖기가 쉽다. 규칙을 정한 반복 추출 과정을 통한 분석 결과가 일정한 패턴을 갖기를 기대하면서 보다 이론적 분포에 가깝거나, 1회적 분석 결과가 갖는 오류 가능성을 축소시키고자 하는 목적으로 부트스크랩 기법을 사용하게 된다.
위의 출력물에서 Confint()의 객체를 LinearModel.1을 쓴 경우, .bs.samples를 쓴 경우, 95% 범위내에서 회귀 계수의 범위가 어떤 차이를 보이는지 비교할 수 있을 것이다. 아래 '모델 > 신뢰 구간...' 기능 설명을 참고할 수 있다.
모델 > 하위셋 모델 선택... Models > Subset model selection...
Linux 사례 (MX 21)
datasets 패키지에 있는 swiss 데이터셋으로 연습해보자. swiss 데이터셋을 불러온다. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기' 메뉴 기능을 선택하여 datasets 패키지에 있는 swiss 데이터셋을 찾고 선택한다. https://rcmdr.tistory.com/184
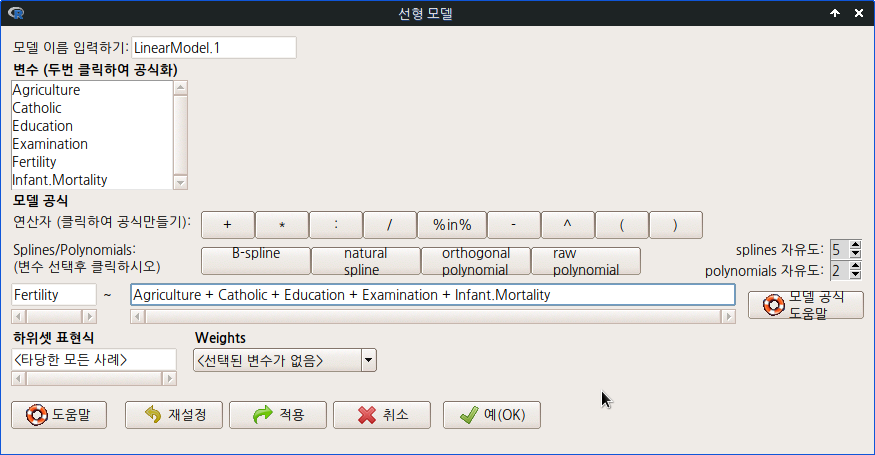
'통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 사용하여 swiss 데이터셋의 변수들 중에서 Fertility를 반응변수로, 나머지를 추천된 설명변수 후보로 가정하고, 선형 모델을 아래와 같이 만든다.
Linux 사례 (MX 21)
data(swiss, package="datasets") # swisss 데이터셋 불러오기
LinearModel.1 <- lm(Fertility ~ Agriculture + Catholic + Education + Examination +
Infant.Mortality, data=swiss) # 문제의식과 연관된 설명변수 후보들을 모두 선택하여 모형만들기
summary(LinearModel.1)
plot(regsubsets(Fertility ~ Agriculture + Catholic + Education + Examination +
Infant.Mortality, data=swiss, nbest=1, nvmax=6), scale='bic')
# 하위셋 모델 선택 그림 만들기
Linux 사례 (MX 21)
그래프에서 bic값이 가장 작은 숫자를 찾고, 이것과 연결된 설명변수 후보들 목록을 살펴보자. 검은색으로 표현된 것은 포함된 것, 흰색(공백)으로 표현된 것은 비포함된 것, 다른 말로 제거되어야 할 것이다. 그래프에서는 Examination 변수가 포함되지 않은 모형의 bic 값이 가장 작은 것을 알려준다.
LinearModel.2 <- lm(Fertility ~ Agriculture + Catholic + Education + Infant.Mortality,
data=swiss) # Examination 변수를 제외한 추천 모형 만들기
summary(LinearModel.2) # LinearModel.2의 요약 정보 보기
plot(regsubsets(Fertility ~ Agriculture + Catholic + Education + Infant.Mortality,
data=swiss, nbest=1, nvmax=5), scale='bic')
# 추천된 하위셋 모델 점검하는 그림 만들기
선형모델에서 유의미한 설명변수들을 찾고 선택하는 것과 관련된 여러 기법이 있다. 아울러 설명변수들 사이의 관계, 서로에 대한 영향력의 크기에 대한 문제의식도 있다. 예를 들어, 데이터셋에 있는 여러개의 변수들 중에서 세개의 변수를 설명변수라고 선택을 했는데, 하나의 설명변수가 나머지에 큰 영향을 미치거나 또는 다른말로 변수들끼리의 연동성의 커서 독립된 설명변수들로 보기 어려운 경우가 발생할 수도 있다. 이 때 설명변수들의 독립성에 관한 점검 기법으로 '분산-팽창 요인(variance-inflation factor)'이 사용된다.
어느 모형이 최적의 모형인가? 여러 모형 중에서 어느 모형을 선택해야 하는가? 많은 모형을 하나씩 하나씩 만들어보는 수고를 하지않고, 보다 신속하고 체계적으로 최적의 모형을 찾는 방법은 없는가? '모델 > 단계적 모델 선택...'기능은 이러한 질문들에 대한 답을 찾는 문제의식과 연관되어 있다.
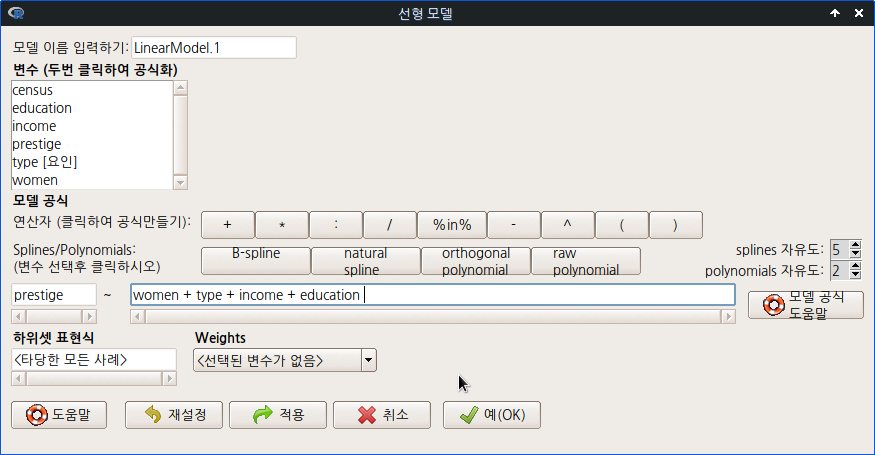
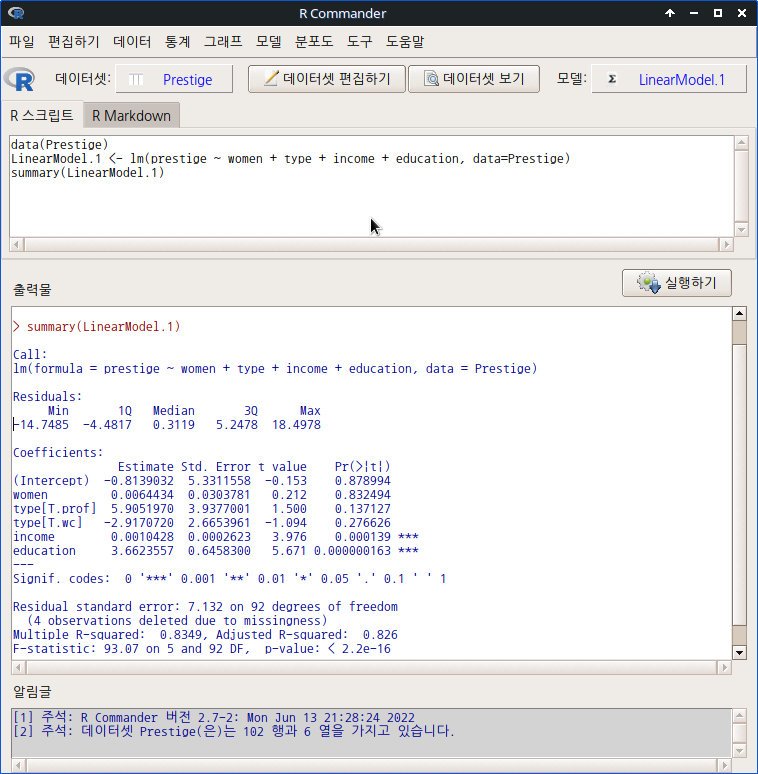
carData 패키지에 있는 Prestige 데이터셋을 활용하여 '단계적 모델 선택...'기능을 연습해보자. 직업의 사회적 권위(prestige)에 영향을 미친다고 생각할 수 있는 변수들은 income, education, type, women 등이라고 먼저 떠올려보자. 이 네개의 설명변수들의 선형적 조합에는 변수 한개씩을 선택하는 경우, 변수 두개를 선택하는 경우, 변수 세개를 선택하는 경우, 그리고 변수 네개를 모두 선택하는 경우 등 매우 다양할 것이다.
data(Prestige) # carData 패키지에 내장된 Prestige 데이터셋 불러오기
LinearModel.1 <- lm(prestige ~ women + type + income + education, data=Prestige)
# 관심가는 설명변수 후보들을 모두 선택하여 선형모델을 우선 만들기
summary(LinearModel.1) # 만든 선형모델의 요약정보 살펴보기
'통계 > 적합성 모델 > 선형 모델...'의 메뉴를 선택하면 아래와 같은 모형 만들기 창이 등장한다. 아래와 같이 변수들을 선택하여 입력하고, 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
아래와 같이 R Commander의 출력창의 내용이 보일 것이다. LinearModel.1이라는 모형의 요약 정보가 출력된다.
Linux 사례 (MX 21)
활성화된 메뉴 기능, '단계적 모델 선택...'을 선택한다.
Linux 사례 (MX 21)
메뉴창에 있는 선택사항, '검색방향'에서 두번째 '전진선택중 변수제거검토'를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
그런데 stepwise() 함수의 연산결과가 나오지 않고, R Commander의 맨 아래에 있는 메세지창에 오류문이 출력된다.
Linux 사례 (MX 21)
stepwise() 함수를 이용할 때, 주의해야 할 사항이 있는데, 단계적으로 생성되는 모델들은 동일한 크기의 데이터셋 행(rows)을 사용해야 한다는 것이다. 그럼 위의 오류문을 이해해보면, 다른 크기의 데이터셋 행이 사용되었다는 것인가. 이 경우, 결측치를 갖고 있는 변수가 있다면, 데이터셋의 행의 크기가 변수에 따라 달라질 수 있는 경우가 발생할 것이다.
'통계 > 요약 > 관찰 결측치 셈하기' 기능을 이용하면 어느 변수에 결측치가 있는지, 그 결측치의 갯수는 몇 개인지를 확인할 수 있다.
Linux 사례 (MX 21)
Prestige 데이터셋의 type 변수에 결측치가 네개 있음을 확인한다. 이 경우 na.omit()를 사용하여 결측치가 있는 행을 제거하자. 그럼 분석에 들어가는 행의 갯수는 98개가 될 것이다.
Start: AIC=406.37은 LinearModel.2의 값으로, 최초의 문제의식이 담긴 설명변수 네개를 모두 포함하고 있다. 그 밑에 있는 차례로 삭제될 변수들 중에서 '- women'의 AIC값은 401.83으로 LinearModel.2의 AIC값 406.37보다 작다. women을 설명변수 목록에서 뺀 모형이 더 적합도가 높다는 뜻이다.
그래서 나온 다음 단계가 'Step: AIC=401.83'이다. 그 아래의 삭제될 변수의 AIC값들은 모두 401.83보다 높다. 추가로 변수를 삭제하지 않는 <none>의 AIC값, 다른 말로 하면 type + income + education 세개의 설명변수를 담고 있는 선형모델이 적합도가 가장 높다는 뜻이다.
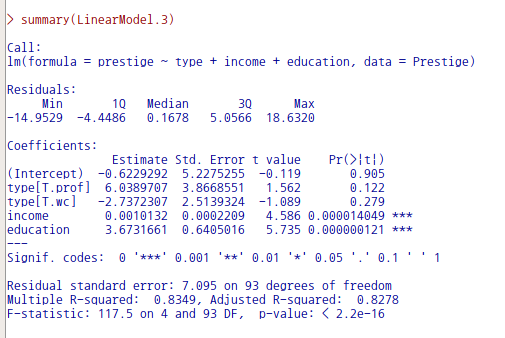
LinearModel.3 <- lm(prestige ~ type + income + education, data=Prestige)
summary(LinearModel.3)
Linux 사례 (MX 21)
위의 LinearModel.3에 대한 요약정보를 살펴보자. 설명변수로 선택된 type, income, education 중에서 type은 income, education과 달리 유의미한 설명력을 갖지 못한다. 그렇다면, type을 제거한 income과 education 두개의 설명변수를 가진 모형이 더 설명력이 높지 않을까하는 궁금증이 생길 수 있다. 하지만, type이 제거된 prestige ~ income + education의 AIC 값은 404.31로 prestige ~ type + income + education의 AIC 값인 401.83보다 크다. 따라서 모형 적합도 차원에서 보면, 유의미한 영향력을 행사하지 못하는 type 변수를 넣는 것이 바람직할 것이다.
그러나, 이러한 수리적인 차원의 모형 적합도 선별은 유의미한 영향력을 행사하는 변수들을 발견하거나, 또는 사전에 세운 가설을 확인하는 차원에서 선택된 설명 변수의 신뢰유의도를 검정하는 목적과 다른 맥락일 수 있다. 물론 상관계수의 크기에 대한 정교한 계산을 위하여 type 변수를 넣은 모형을 선택할 수 있으나, 보다 광의적으로 생각하면 분석 대상으로 들어온 데이터셋 자체가 가지는 한계(크기, 모집단 반영, 향후 미래적 예측력)가 있기 때문에 사회과학 입장에서 매우 예민하게 고민할 필요가 있을까라는 질문을 받을 수 있다.
한편, '단계적 모델 선택...'기능에서 'BIC'가 선택된 기본설정을 그대로 사용하였음에도 불구하고, 분석의 내용에는 모두 AIC로 되어 있다. 이 상황에 대한 설명은 stepwise() 함수의 도움말에 나와있다:
?stepwise # RcmdrMisc 패키지에 포함된 함수로서, 먼저 Rcmdr 패키지가 호출된 상황임을 전제한다.
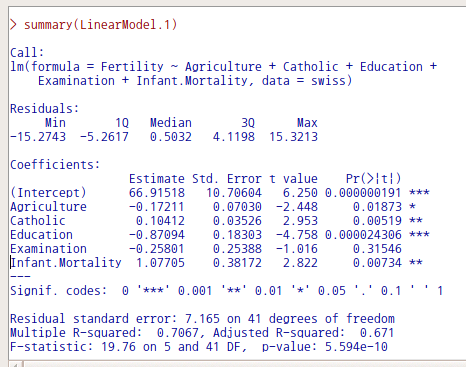
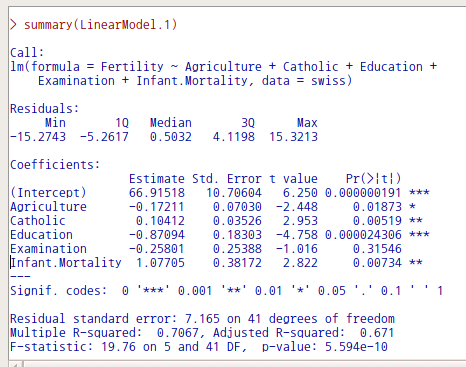
datasets 패키지에 있는 swiss 데이터셋은 1880년대 스위스 지방의 출산율과 사회경제적인 요인들에 대한 정보를 담고있다. 출산율(Fertility)에 영향을 미치는 요인들을 찾고, 설명력 높은 모형을 선택하고자 하는 과정이 필요하다. 다중회귀분석 기법을 활용한 선형모델을 만들고 계산하였다고 가정하자.
LinearModel.1과 LinearModel.2를 비교해보면, 설명변수에 Examination이 포함되어 있는가 여부이다. Examination 변수는 스위스의 지방별로 'draftees receiving highest mark on army examination'의 %를 사례값으로 담고 있다. 두 모형의 분석결과, 특히 Examination 변수의 유무에 따른 차이를 꼼꼼히 살펴보자.
LinearModel.1을 살펴보면, Examination 변수는 Fertility 변수에 유의미한 영향력을 미친다고 보기 어렵다. 그렇다면, LinearModel.1과 LinearModel.2에서 어느 모형을 선택해야 하는가? 두 모형의 Multiple R-squared, Adjusted R-squared, F-statistic, p-value 등은 작은 차이를 나타낸다.
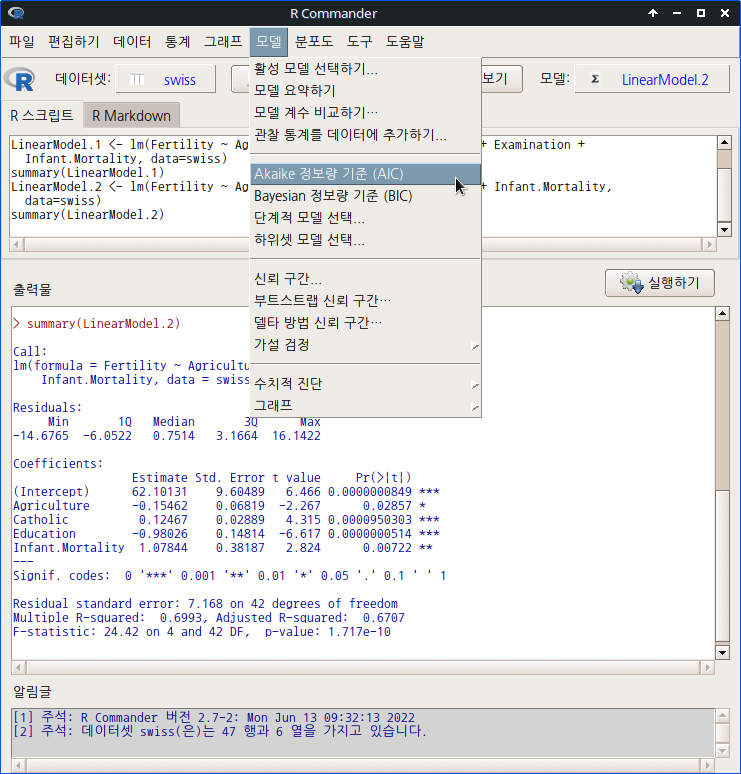
이 때 사용하는 방법의 하나가 Bayesian 정보량 기준 (BIC)이다. 'When comparing models fitted by maximum likelihood to the same data, the smaller the AIC or BIC, the better the fit.' 최대우도 또는 최대가능도 기법을 통하여 모형들을 비교할 때, 상대적으로 작은 값이 보다 적합도가 높다는 뜻이다. 결국 LinearModel.1과 LinearModel.2에서 어느 모형의 BIC 값이 더 작은가를 확인하여 보다 적합도가 높은 모형을 선택하고자 하는 것이다.
LinearModel.2의 BIC 값이 LinearModel.1의 BIC 값보다 미세하지만 더 작다. LinearModel.2가 더 적합도가 높은 모형이다라고 할 수 있다. 1880년대 스위스 지방의 출산율(Fertility)에 관한 사회경제적 요인들을 찾고, 설명변수들의 영향력을 점검할 때 Examination 변수를 제외한 모형을 사용하는 것이 바람직하다는 선택으로 이끌게 된다.
datasets 패키지에 있는 swiss 데이터셋은 1880년대 스위스 지방의 출산율과 사회경제적인 요인들에 대한 정보를 담고있다. 출산율(Fertility)에 영향을 미치는 요인들을 찾고, 설명력 높은 모형을 선택하고자 하는 과정이 필요하다. 다중회귀분석 기법을 활용한 선형모델을 만들고 계산하였다고 가정하자.
LinearModel.1과 LinearModel.2를 비교해보면, 설명변수에 Examination이 포함되어 있는가 여부이다. Examination 변수는 스위스의 지방별로 'draftees receiving highest mark on army examination'의 %를 사례값으로 담고 있다. 두 모형의 분석결과, 특히 Examination 변수의 유무에 따른 차이를 꼼꼼히 살펴보자.
LinearModel.1을 살펴보면, Examination 변수는 Fertility 변수에 유의미한 영향력을 미친다고 보기 어렵다. 그렇다면, LinearModel.1과 LinearModel.2에서 어느 모형을 선택해야 하는가? 두 모형의 Multiple R-squared, Adjusted R-squared, F-statistic, p-value 등은 작은 차이를 나타낸다.
이 때 사용하는 방법의 하나가 Akaike 정보량 기준 (AIC)이다. 'When comparing models fitted by maximum likelihood to the same data, the smaller the AIC or BIC, the better the fit.' 최대우도 또는 최대가능도 기법을 통하여 모형들을 비교할 때, 상대적으로 작은 값이 보다 적합도가 높다는 뜻이다. 결국 LinearModel.1과 LinearModel.2에서 어느 모형의 AIC 값이 더 작은가를 확인하여 보다 적합도가 높은 모형을 선택하고자 하는 것이다.
LinearModel.2의 AIC 값이 LinearModel.1의 AIC 값보다 미세하지만 더 작다. LinearModel.2가 더 적합도가 높은 모형이다라고 할 수 있다. 1880년대 스위스 지방의 출산율(Fertility)에 관한 사회경제적 요인들을 찾고, 설명변수들의 영향력을 점검할 때 Examination 변수를 제외한 모형을 사용하는 것이 바람직하다는 선택으로 이끌게 된다.
하나의 데이터셋을 대상으로 가장 최적의 분석모형을 찾고자 할 때, 또는 보다 정교한 설명을 위하여 만들어진 모형들을 비교하고자 할 때 사용하는 기능이다.
예를 들어, carData에 포함된 Prestige 데이터셋을 이용하여 연습해보자. 직업의 사회적 권위(prestige)에 영향을 미치는 두 개의 독립변수(설명변수)를 교육기간(education)과 수입(income)이라고 가정하자. 그런데 education과 income의 선형적 관계에 대한 보다 깊은 고민을 한다고 생각해보자. education과 income이 서로 독립적인 선형관계로 prestige에 영향을 줄 수도 있고, 또 education과 income이 독립적인 영향을 줄 뿐 만 아니라, 서로 상호작용을 일으키면서 prestige에 영향을 추가 할 수 도 있다고 주장할 수 있다. 이러한 문제의식에서 아래와 같은 두개의 모형을 만들고 또 이 두개의 모형 중에서 어느것이 더 정교한지를 찾는다고 생각해보자.
참고로 연산자 +는 설명변수들의 독립적 선형관계를, *는 독립적 선형관계와 결합적 선형관계를 함께 계산하는데 사용한다.
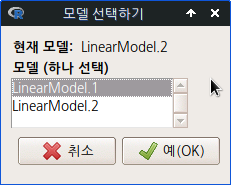
LinearModel.1과 LinearModel.2라는 두 개의 모형을 만들고 두 개의 모델을 비교하는 방법이다. 모델 > 가설 검정 > 두 모델 비교하기...의 메뉴를 선택하면, 만들어 놓은 두 개의 모형을 비교하는 기능을 이용할 수 있다. 직관적으로 두개의 모형을 차례로 선택해보자. 그리고 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
R Commander 출력창에 다음과 같은 결과가 출력될 것이다. 출력 내용은 모델 1과 모델 2의 차이가 유의미하며 (Pr(>F)), 모델 2가 보다 설명력이 높다(Sum of sq > 0 또는 RSS < 0)는 뜻으로 해석할 수 있다.