통계 > 차원 분석 > 군집 분석 > 위계 군집 분석...
Statistics > Dimensional analysis > Cluster analysis > Hierarchical cluster analysis...
datasets 패키지에 있는 USArrests 데이터셋을 활용해서, 위계 군집 분석을 연습해보자. 우선 USArrests 데이터셋을 활성화시킨다.
USArrests 데이터셋
datasets > USArrests data(USArrests, package="datasets") R Commander 화면 상단에서 <데이터셋 보기> 버튼을 누르면 아래와 같은 내부 구성을 확인할 수 있다. help("USArrests") USArrests {datasets} R Do..
rcmdr.kr
<위계적 군집화> 창에서 아래와 같이 변수 네개를 모두 선택한다. 그리고, 기본으로 추천되는 HClust.1를 군집화 이름으로 사용하자.

<선택기능> 창에서 기본설정된 사항들을 그대로 사용해보자. <군집화 방법>, <거리 측정>, <덴드로그램 그리기> 등을 살펴본다.

예(OK) 버튼을 누르면, 아래와 같은 그래픽 창이 등장한다.
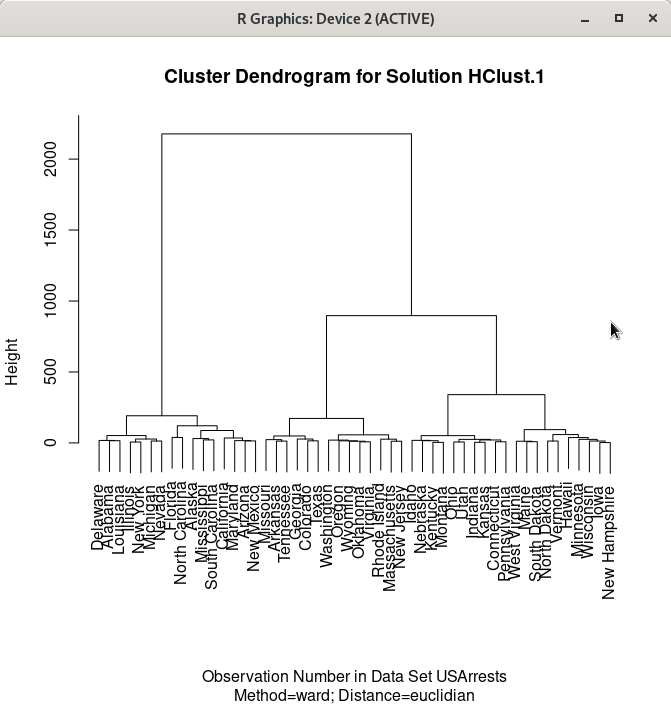
data(USArrests, package="datasets")
HClust.1 <- hclust(dist(model.matrix(~-1 + Assault+Murder+Rape+UrbanPop, USArrests)) , method=
"ward")
plot(HClust.1, main= "Cluster Dendrogram for Solution HClust.1", xlab=
"Observation Number in Data Set USArrests", sub="Method=ward; Distance=euclidian")
'Statistics > Dimensional analysis' 카테고리의 다른 글
| 5.4. Add hierarchical clustering to data set... (0) | 2022.03.20 |
|---|---|
| 5.3. Summarize hierarchical clustering... (0) | 2022.03.20 |
| 5.1. k-means cluster analysis... (0) | 2022.03.18 |
| 3. factor analysis... (0) | 2022.03.08 |
| 2. Principal-components analysis... (0) | 2022.03.08 |








