통계 > 비모수 검정 > 일-표본 Wilcoxon 검정...
Statistics > Nonparametric tests > Single-sample Wilcoxon test...
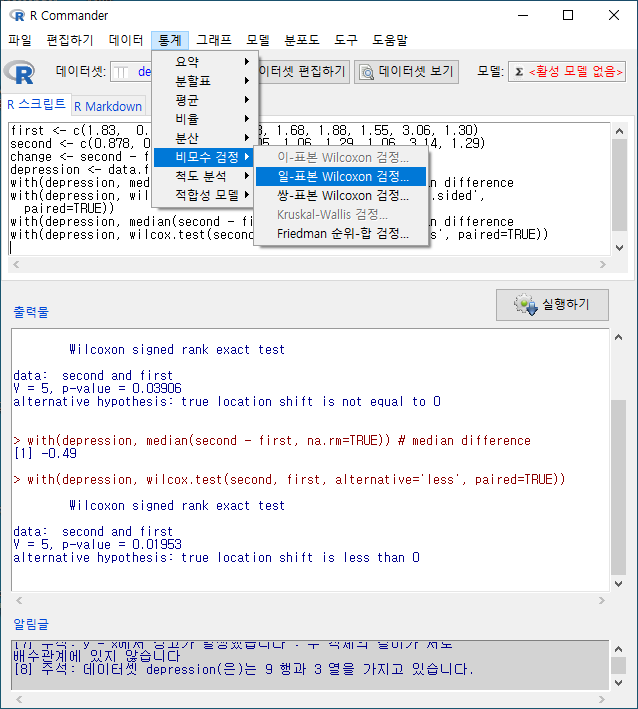
먼저 '통계 > 비모수 검정 > 쌍-표본 Wilcoxon 검정...'을 살펴보는 것을 추천한다. depression 이라는 데이터셋을 만들고, 변수 first, second, change를 만들었다. change는 second와 first의 차이에 관련 사례 값을 갖는다.
3. Paired-samples Wilcoxon test...
통계 > 비모수 검정 > 쌍-표본 Wilcoxon test... Statistics > Nonparametric tests > Paired-samples Wilcoxon test... depression 이라는 이름의 데이터셋을 만들자. first, second, change 라는 세개의 변수를..
rcmdr.kr
'통계 > 비모수 검정 > 일-표본 Wilcoxon 검정...'은 depression 데이터셋의 change 변수처럼 두 개 변수의 차이를 갖는 (또는 차이가 계산된) 변수를 기준값과 비교하여 차이 검정을 하는 기법이다. 때로는 특정 변수와 기준 값의 비교를 통하여 검정을 하기도 한다.

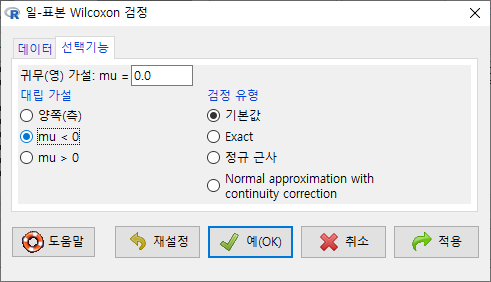
데이터셋과 변수에 대한 의미적 판단이 깊은 경우 <대립 가설>의 선택을 다양하게 결정할 수 있다. 아래 화면에서 'mu < 0'은 change가 귀무(영) 가설, mu=0.0 일 때 depression 의 변화가 작아졌음을 확인하는 것으로 이해할 수 있다.
with(depression, median(change, na.rm=TRUE))
with(depression, mean(change, na.rm=TRUE))
with(depression, wilcox.test(change, alternative='less', mu=0.0))출력 창에 아래와 같이 검정의 통계적 정보가 제공된다:

'Statistics > Nonparametric tests' 카테고리의 다른 글
| 3. Paired-samples Wilcoxon test... (0) | 2022.03.21 |
|---|---|
| 1. Two-sample Wilcoxon test... (0) | 2022.03.21 |
| 5. Friedman rank-sum test... (0) | 2022.03.20 |
| 4. Kruskal-Wallis test... (0) | 2022.03.09 |