데이터 > 활성 데이터셋 > 활성 데이터셋 내보내기...
Data > Active data set > Export active data set...
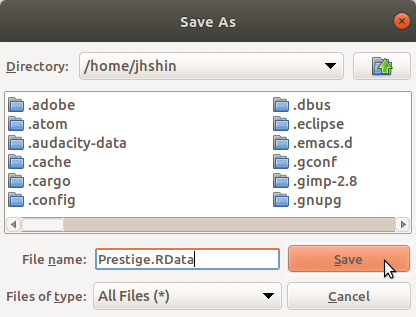
작업을 마친/ 또는 다른 업무를 위하여 일시적으로 작업한 자료를 하드디스크에 저장하는 경우가 흔하다. .RData로 자료를 저장할 수 있고, 공동작업자와 공유할 수 있지만, 행여 R을 사용하지 않는 분석가/사용자에게 자료를 보내야 하는 경우가 있다. 이 때 사용하는 기능이다.

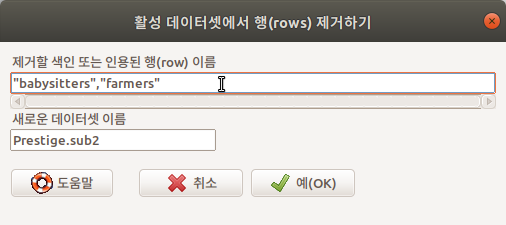
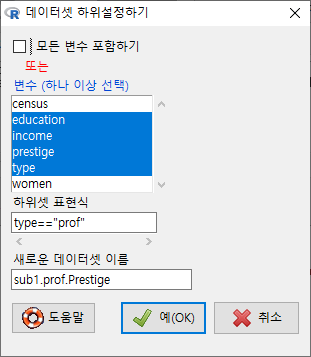
자료를 텍스트 형식으로 저장하는 경우 다른 도구 사용자(예, 엑셀, PSPP 등)가 쉽게 불러와서 추가 작업을 할 수 있을 것이다. 변수, 행, 문자 등에 대하여 지정하는 옵션이 있다. 결측값 표현 방식도 정할 수 있다. 중요한 것은 필드 구분자이다. 쉼표(,)를 기준으로하는 필드는 .csv로 파일이 저장되고, 여백-탭-세미콜론 등으로 필드 구분자를 지정하면 .txt로 저장된다.
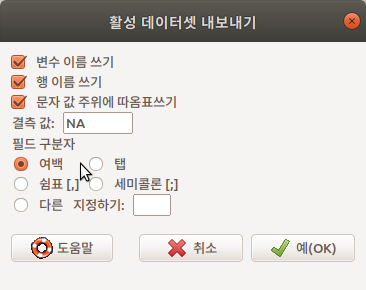

쉼표(',')를 필드 구분자로 사용하는 경우, 내보내는 데이터셋의 확장자는 .csv로 저장된다.


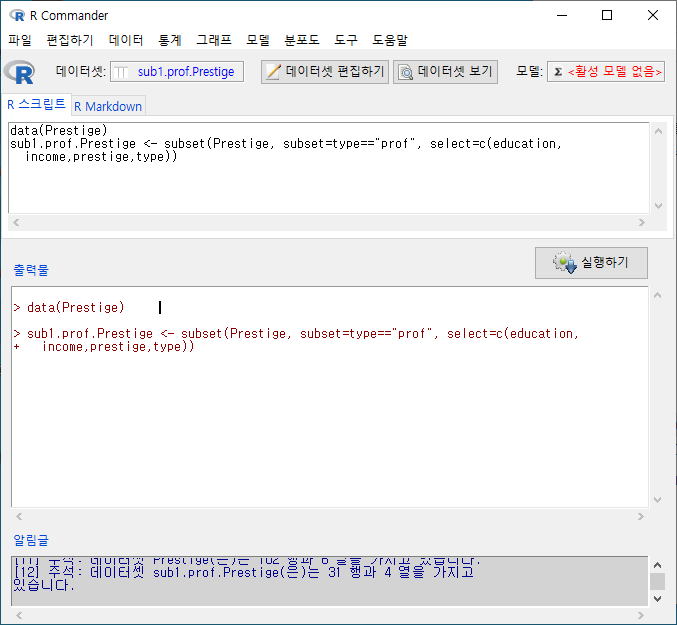
write.table() 함수를 사용한다.
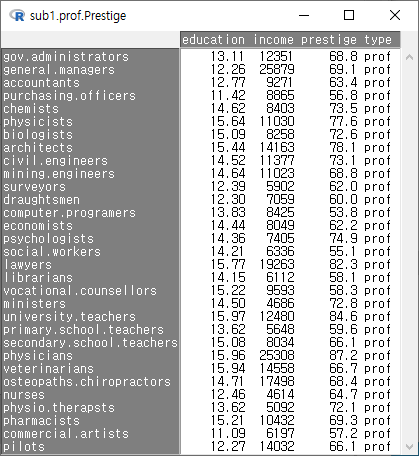
write.table(활성데이터셋, "경로/파일이름.확장자, sep="필드구분자", col.names=, row.names=, quote=, na="결측치표시")
신경써야 할 것이 하나 더 있다. 대화창에는 등장하지 않지만, 현재 작업하는 컴퓨터의 인코딩 방식으로 자료가 내보내진다. 이 경우 윈도우-맥 애플-리눅스 등의 이기종간 자료 교환에는 인코딩 호환 문제가 발생할 수 있다. Linux는 utf-8, Windows는 cp949를 기본 인코딩으로 사용한다.
write.table(x, file = "", append = FALSE, quote = TRUE, sep = " ",
eol = "\n", na = "NA", dec = ".", row.names = TRUE,
col.names = TRUE, qmethod = c("escape", "double"),
fileEncoding = "")또 하나, 불편한 점이 있다. <행 이름 쓰기>와 관련된 것이다. <행 이름 쓰기>를 하고 저장한 파일에는 변수이름이 한자리 앞으로 오는 문제가 있다. 행 이름 위의 빈 칸에 첫 변수 이름이 쓰여지기 때문이다. 엑셀이나 다른 도구에서 행 이름 위에 있는 변수 이름을 이동시켜야 하는 불편함이 있다. 그렇다고 행 이름을 안쓰는 것도 문제가 될 수 있다. 일련번호는 상관없겠으나 사례 이름이 삭제되면 정보량이 축소되기 때문이다. 그래서 사례이름을 추가적인 변수명으로 사용하는 꼼수가 흔한 상황이다.
?write.table # utils 패키지의 write.table 도움말 보기
## Not run:
## To write a CSV file for input to Excel one might use
x <- data.frame(a = I("a \" quote"), b = pi)
write.table(x, file = "foo.csv", sep = ",", col.names = NA,
qmethod = "double")
## and to read this file back into R one needs
read.table("foo.csv", header = TRUE, sep = ",", row.names = 1)
## NB: you do need to specify a separator if qmethod = "double".
### Alternatively
write.csv(x, file = "foo.csv")
read.csv("foo.csv", row.names = 1)
## or without row names
write.csv(x, file = "foo.csv", row.names = FALSE)
read.csv("foo.csv")
## To write a file in Mac Roman for simple use in Mac Excel 2004/8
write.csv(x, file = "foo.csv", fileEncoding = "macroman")
## or for Windows Excel 2007/10
write.csv(x, file = "foo.csv", fileEncoding = "UTF-16LE")
## End(Not run)'Data > Active data set' 카테고리의 다른 글
| 14. Reshape data set from wide to long format... (0) | 2022.02.10 |
|---|---|
| 13. Reshape data set from long to wide format... (0) | 2022.02.10 |
| 16. Save active data set... (0) | 2019.09.08 |
| 12. Remove cases with missing data... (0) | 2019.09.08 |
| 11. Stack variables in active data set... (0) | 2019.09.08 |