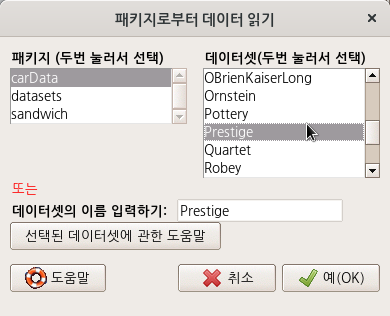
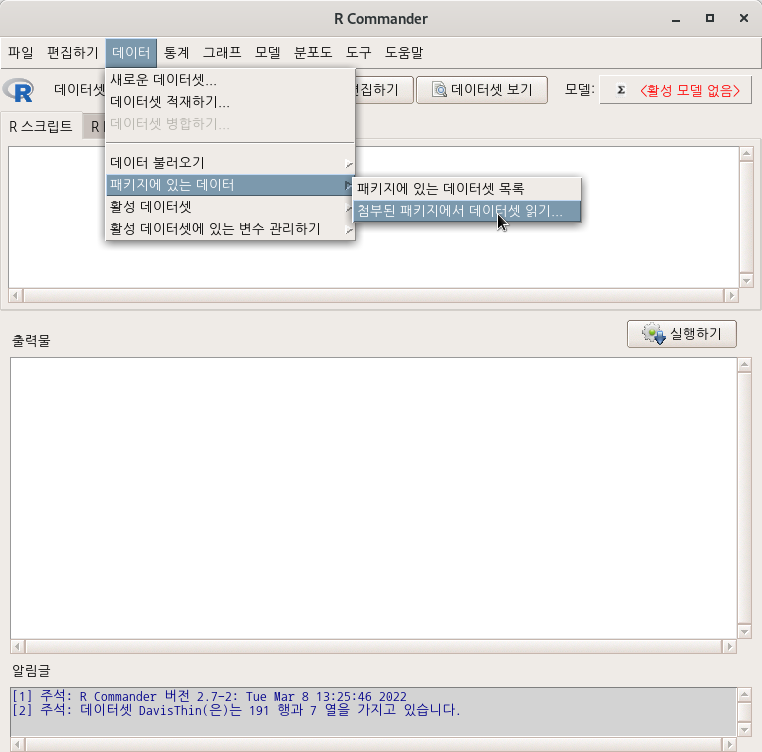
R에는 많은 패키지가 있으며, 그 패키지에는 많은 경우 데이터셋을 포함하고 있다. 그 데이터셋에 대한 도움말을 볼 수 있는 기능이다. 생각해보라. 예제 데이터셋을 통하여 함수를 연습하는데, 데이터셋의 특성을 알지 못한다면 분석과 시각화에 필요한 통찰력을 얻을 수 있겠는가.
위의 화면은 MASS 패키지가 적재되었고, 또 그 안에 포함된 housing 이라는 데이터셋이 활성화된 상태에서 '도움말 > 활성 데이터셋에 관한 도움말 (만약 이용가능하다면)' 메뉴 기능을 이용할 수 있다는 것이다. 해당 메뉴를 선택하면, 새로운 웹 브라우저 창이 등장하면서, 활성 데이터셋의 도움말이 제공될 것이다.
Linux 사례 (MX 21)
help("housing") # housing 데이터셋 도움말 보기
?housing # housing 데이터셋 도움말 보기 (? 활용)
The “experimenters” were the actual subjects of the study. They collected ratings of the apparent success of people in pictures who were pre-selected for their average appearance of success. The experimenters were told prior to collecting data that particular subjects were either high or low in their tendency to rate appearance of success, and were instructed to get good data, scientific data, or were given no such instruction. Each experimenter collected ratings from 18 randomly assigned subjects. This version of the Adler data is taken from Erickson and Nosanchuk (1977). The data described in the original source, Adler (1973), have a more complex structure.
Usage
Adler
Format
This data frame contains the following columns:
instruction
a factor with levels:good, good data;none, no stress;scientific, scientific data.
expectation
a factor with levels:high, expect high ratings;low, expect low ratings.
rating
The average rating obtained.
Source
Erickson, B. H., and Nosanchuk, T. A. (1977)Understanding Data.McGraw-Hill Ryerson.
References
Adler, N. E. (1973) Impact of prior sets given experimenters and subjects on the experimenter expectancy effect.Sociometry36, 113–126.
TheCowlesdata frame has 1421 rows and 4 columns. These data come from a study of the personality determinants of volunteering for psychological research.
Usage
Cowles
Format
This data frame contains the following columns:
neuroticism
scale from Eysenck personality inventory
extraversion
scale from Eysenck personality inventory
sex
a factor with levels:female;male
volunteer
volunteeing, a factor with levels:no;yes
Source
Cowles, M. and C. Davis (1987) The subject matter of psychology: Volunteers.British Journal of Social Psychology26, 97–102.
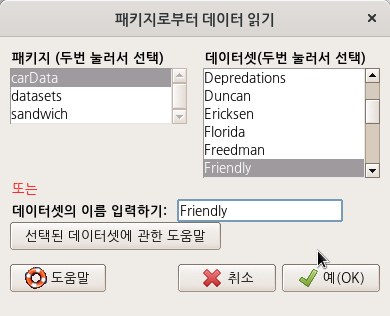
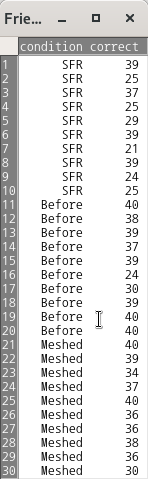
TheFriendlydata frame has 30 rows and 2 columns. The data are from an experiment on subjects' ability to remember words based on the presentation format.
Usage
Friendly
Format
This data frame contains the following columns:
condition
A factor with levels:Before, Recalled words presented before others;Meshed, Recalled words meshed with others;SFR, Standard free recall.
correct
Number of words correctly recalled, out of 40 on final trial of the experiment.
Source
Friendly, M. and Franklin, P. (1980) Interactive presentation in multitrial free recall.Memory and Cognition8265–270 [Personal communication from M. Friendly].
References
Fox, J. (2016)Applied Regression Analysis and Generalized Linear Models, Third Edition. Sage.
Fox, J. and Weisberg, S. (2019)An R Companion to Applied Regression, Third Edition, Sage.
R Commander 화면 상단에서 <데이터셋 보기> 버튼을 누르면 아래와 같은 내부 구성을 확인할 수 있다.
Linux 사례 (MX 21)
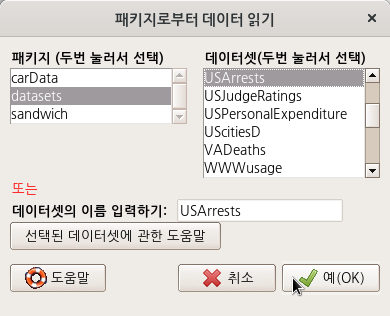
help("USArrests")
USArrests {datasets}
R Documentation
Violent Crime Rates by US State
Description
This data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 US states in 1973. Also given is the percent of the population living in urban areas.
Usage
USArrests
Format
A data frame with 50 observations on 4 variables.
[,1]
Murder
numeric
Murder arrests (per 100,000)
[,2]
Assault
numeric
Assault arrests (per 100,000)
[,3]
UrbanPop
numeric
Percent urban population
[,4]
Rape
numeric
Rape arrests (per 100,000)
Note
USArrestscontains the data as in McNeil's monograph. For theUrbanPoppercentages, a review of the table (No. 21) in the Statistical Abstracts 1975 reveals a transcription error for Maryland (and that McNeil used the same “round to even” rule thatR'sround()uses), as found by Daniel S Coven (Arizona).
See the example below on how to correct the error and improve accuracy for the ‘<n>.5’ percentages.
Source
World Almanac and Book of facts 1975. (Crime rates).
TheMooredata frame has 45 rows and 4 columns. The data are for subjects in a social-psychological experiment, who were faced with manipulated disagreement from a partner of either of low or high status. The subjects could either conform to the partner's judgment or stick with their own judgment.
Usage
Moore
Format
This data frame contains the following columns:
partner.status
Partner's status. A factor with levels:high,low.
conformity
Number of conforming responses in 40 critical trials.
fcategory
F-Scale Categorized. A factor with levels (note levels out of order):high,low,medium.
fscore
Authoritarianism: F-Scale score.
Source
Moore, J. C., Jr. and Krupat, E. (1971) Relationship between source status, authoritarianism and conformity in a social setting.Sociometry34, 122–134.
Personal communication from J. Moore, Department of Sociology, York University.
References
Fox, J. (2016)Applied Regression Analysis and Generalized Linear Models, Third Edition. Sage.
Fox, J. and Weisberg, S. (2019)An R Companion to Applied Regression, Third Edition, Sage.
TheDavisThindata frame has 191 rows and 7 columns. This is part of a larger dataset for a study of eating disorders. The seven variables in the data frame comprise a "drive for thinness" scale, to be formed by summing the items.
Usage
DavisThin
Format
This data frame contains the following columns:
DT1
a numeric vector
DT2
a numeric vector
DT3
a numeric vector
DT4
a numeric vector
DT5
a numeric vector
DT6
a numeric vector
DT7
a numeric vector
Source
Davis, C., G. Claridge, and D. Cerullo (1997) Personality factors predisposing to weight preoccupation: A continuum approach to the association between eating disorders and personality disorders.Journal of Psychiatric Research31, 467–480. [personal communication from the authors.]
References
Fox, J. and Weisberg, S. (2019)An R Companion to Applied Regression, Third Edition, Sage.