통계 > 비모수 검정 > 이-표본 Wilcoxon 검정...
Statistics > Nonparametric tests > Two-sample Wilcoxon test...

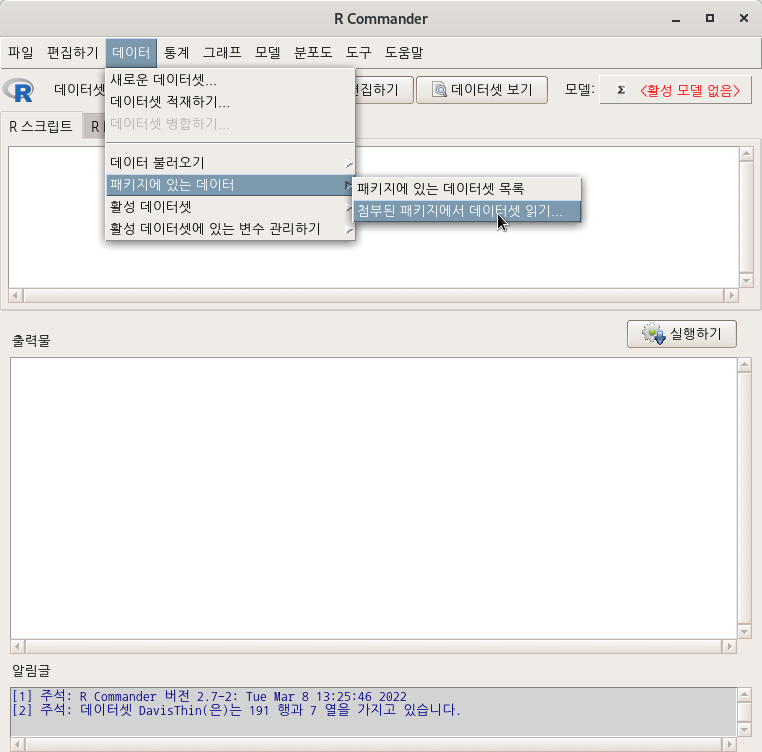
'통계 > 비모수 검정 > 이-표본 Wilcoxon 검정...' 기능을 이용하기 위해서 데이터셋을 선택하고, 정비해보자. datasets 패키지에 있는 airquality 데이터셋을 선택하고, 그 안에 있는 변수 Month 사례 값들 중에서 5월, 8월에 해당하는 5, 8을 선택한 하위 데이터셋을 만들고, airquality.sub라 이름 붙이자. 그리고, 5, 8을 요인화 시켜서, May, August라고 수준을 만들자.
airquality 데이터셋
datasets > airquality R이 시작될 때, datasets 패키지가 자동으로 호출된다. 따라서 R Commander를 실행할 때, datasets 패키지는 첨부 패키지화되어 메뉴창을 통해서 내부 데이터셋을 찾고 불러올 수 있다.
rcmdr.kr
data(airquality, package="datasets") # airquality 데이터셋 불러오기
airquality.sub <- subset(airquality, subset=Month %in% c(5, 8))
# 5월, 8월만 포함하는 하위셋 만들기
summary(airquality.sub)
airquality.sub <- within(airquality.sub, {
Month.f <- factor(Month, labels=c('May','August'))
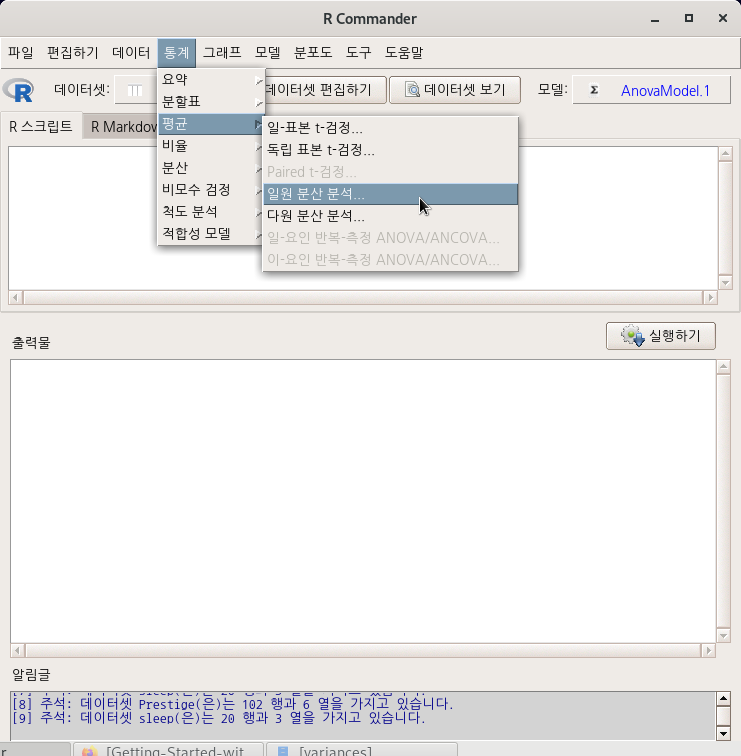
}) # Month.f라는 요인형 변수 만들기집단 변수인 Month.f는 두개의 수준을 갖고 있고, 이 두개의 수준을 기준으로 Ozone을 비교하는 것이다.

<선택기능> 창에 있는 기본 설정을 우선 그대로 사용해보자. 향후 데이터셋과 변수에 대한 이해력이 높아지면, 다양한 선택을 할 수 있다.

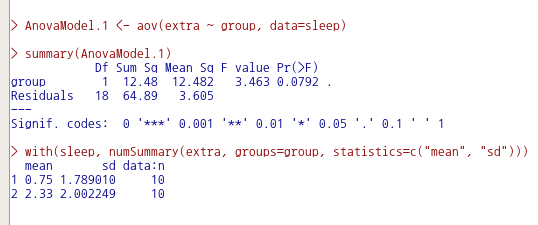
Tapply(Ozone ~ Month.f, median, na.action=na.omit, data=airquality.sub)
# medians by group
wilcox.test(Ozone ~ Month.f, alternative="two.sided", data=airquality.sub)
'Statistics > Nonparametric tests' 카테고리의 다른 글
| 3. Paired-samples Wilcoxon test... (0) | 2022.03.21 |
|---|---|
| 2. Single-sample Wilcoxon test... (0) | 2022.03.21 |
| 5. Friedman rank-sum test... (0) | 2022.03.20 |
| 4. Kruskal-Wallis test... (0) | 2022.03.09 |