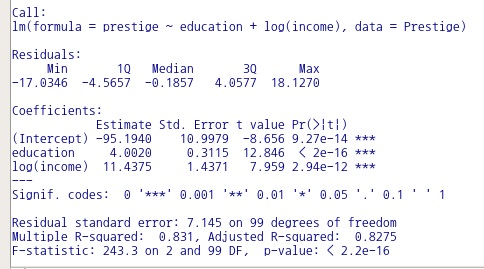
datasets::faithful


data(faithful, package="datasets")
summary(faithful)
str(faithful)
데이터셋의 내부는 다음과 같다:

?faithful # datasets 패키지에 포함된 faithful 데이터셋 도움말 보기
| faithful {datasets} | R Documentation |
Old Faithful Geyser Data
Description
Waiting time between eruptions and the duration of the eruption for the Old Faithful geyser in Yellowstone National Park, Wyoming, USA.
Usage
faithfulFormat
A data frame with 272 observations on 2 variables.
| [,1] | eruptions | numeric | Eruption time in mins |
| [,2] | waiting | numeric | Waiting time to next eruption (in mins) |
Details
A closer look at faithful$eruptions reveals that these are heavily rounded times originally in seconds, where multiples of 5 are more frequent than expected under non-human measurement. For a better version of the eruption times, see the example below.
There are many versions of this dataset around: Azzalini and Bowman (1990) use a more complete version.
Source
W. Härdle.
References
Härdle, W. (1991). Smoothing Techniques with Implementation in S. New York: Springer.
Azzalini, A. and Bowman, A. W. (1990). A look at some data on the Old Faithful geyser. Applied Statistics, 39, 357–365. doi: 10.2307/2347385.
See Also
geyser in package MASS for the Azzalini–Bowman version.
Examples
require(stats); require(graphics)
f.tit <- "faithful data: Eruptions of Old Faithful"
ne60 <- round(e60 <- 60 * faithful$eruptions)
all.equal(e60, ne60) # relative diff. ~ 1/10000
table(zapsmall(abs(e60 - ne60))) # 0, 0.02 or 0.04
faithful$better.eruptions <- ne60 / 60
te <- table(ne60)
te[te >= 4] # (too) many multiples of 5 !
plot(names(te), te, type = "h", main = f.tit, xlab = "Eruption time (sec)")
plot(faithful[, -3], main = f.tit,
xlab = "Eruption time (min)",
ylab = "Waiting time to next eruption (min)")
lines(lowess(faithful$eruptions, faithful$waiting, f = 2/3, iter = 3),
col = "red")
'Dataset_info > faithful' 카테고리의 다른 글
| faithful 데이터셋 예제 (0) | 2022.07.25 |
|---|