데이터 > 활성 데이터셋의 변수 관리하기 > 문자 변수를 요인으로 변환하기...
Data > Manage variables in active data set > Convert character variables to factors...

활성화된 데이터셋이 있는 경우에도 <문자 변수를 요인으로 변환하기...> 기능이 비활성화되어있는 때가 있다. 이 상황은 활성화된 데이터셋에 문자 변수가 없는 경우이다.
문자 변수를 갖고 있는 데이셋을 만들어(또는 불러와) 이 기능을 활성화시키자. carData 패키지의 Prestige 데이터셋을 Prestige.csv 파일로 내보냈다고 하자.
https://rcmdr.tistory.com/52
17. Export active data set...
활성 데이터셋 내보내기... Data > Active data set > Export active data set... 작업을 마친/ 또는 다른 업무를 위하여 일시적으로 작업한 자료를 하드디스크에 저장하는 경우가 흔하다. .RData로 자료를 저장
rcmdr.tistory.com
참고로 이 블로그에 Prestige.csv 파일을 올려놓았다. 바로 내려받아 사용할 수 있다.
https://rcmdr.tistory.com/98
Prestige_csv
carData 패키지에 있는 Prestige 데이터셋을 .csv로 저장하여 내보낼 수 있다. Active data set > Export active data set..." href="https://rcmdr.tistory.com/52" target="_blank" rel="noopener">https://rcm..
rcmdr.tistory.com
이 파일을 <데이터 불러오기> 기능을 통하여 다시 불러보자. 갖고 있는 어떤 .csv파일을 불러오는 것과 같은 사례로 이해할 수 있다. 이 경우는 Data > 데이터 불러오기 > TXT 파일, 클립보드 또는 URL에서... 의 기능을 사용하는 것이다.
https://rcmdr.tistory.com/29
from text file, clipboard, or URL...
(한글 번역을 하지 않았다) Data > Import data > from text file, clipboard, or URL... 개인적인 경험과 판단이지만, R에서 외부 데이터 파일을 불러오는 것을 초급자들은 너무 어려워한다. 쉽지 않다. 분석과..
rcmdr.tistory.com
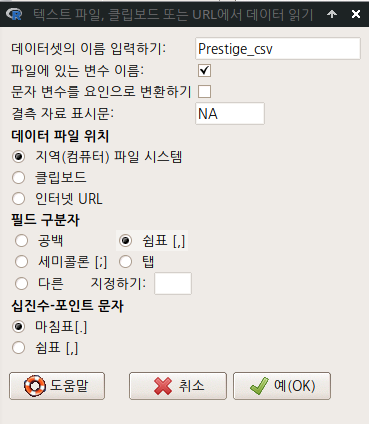
1. 불러올 데이터셋 파일의 이름은 Prestige.csv, 저장될 데이터셋 객체의 이름을 Prestige_csv라고 하자.
2. <문자 변수를 요인으로 변환하기>에 있는 클릭을 제거하자.
3. 필드 구분자를 <쉼표 [,]>로 선택하자.
4. 그리고 새롭게 열리는 디렉토리 창에서 Prestige.csv 파일을 찾아 선택하자.
Prestige 데이터셋과 달리, Prestige_csv 데이터셋의 type 변수는 요인이 아닌 문자형이다.

문자형 변수가 포함된 Prestige_csv 데이터셋이 활성화되면, <문자 변수를 요인으로 변환하기...> 기능이 활성화된다.
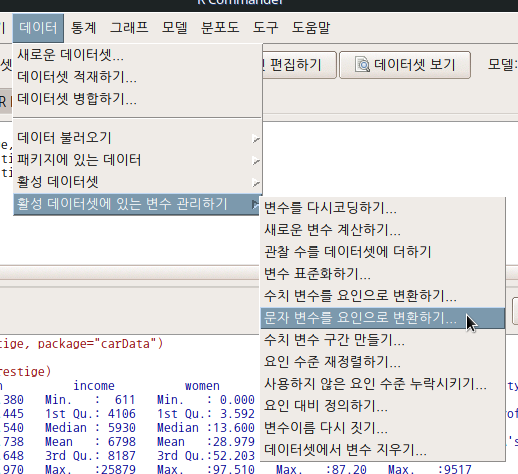
문자형 변수 목록에 type 변수가 보인다. <다중 변수를 위한 새로운 변수 이름 또는 접미사>에 변환시킬문자형변수.f를 넣고, 기존 type 변수와 비교해보자. 예(OK) 버톤을 누른다.

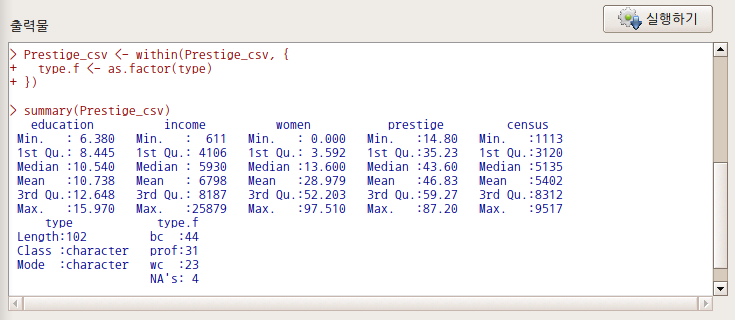
활성데이터셋 <- within(활성데이터셋, { 새로운변수이름 <- as.factor(변환시킬문자형변수) })
Prestige_csv <- within(Prestige_csv, { type.f <- as.factor(type) })출력창 아래에 있는 type 변수와 type.f 변수를 비교해보자. type.f 변수는 요인형으로 전환되어 있다.
?as.factor # base 패키지의 as.factor 도움말 보기
(ff <- factor(substring("statistics", 1:10, 1:10), levels = letters))
as.integer(ff) # the internal codes
(f. <- factor(ff)) # drops the levels that do not occur
ff[, drop = TRUE] # the same, more transparently
factor(letters[1:20], labels = "letter")
class(ordered(4:1)) # "ordered", inheriting from "factor"
z <- factor(LETTERS[3:1], ordered = TRUE)
## and "relational" methods work:
stopifnot(sort(z)[c(1,3)] == range(z), min(z) < max(z))
## suppose you want "NA" as a level, and to allow missing values.
(x <- factor(c(1, 2, NA), exclude = NULL))
is.na(x)[2] <- TRUE
x # [1] 1 <NA> <NA>
is.na(x)
# [1] FALSE TRUE FALSE
## More rational, since R 3.4.0 :
factor(c(1:2, NA), exclude = "" ) # keeps <NA> , as
factor(c(1:2, NA), exclude = NULL) # always did
## exclude = <character>
z # ordered levels 'A < B < C'
factor(z, exclude = "C") # does exclude
factor(z, exclude = "B") # ditto
## Now, labels maybe duplicated:
## factor() with duplicated labels allowing to "merge levels"
x <- c("Man", "Male", "Man", "Lady", "Female")
## Map from 4 different values to only two levels:
(xf <- factor(x, levels = c("Male", "Man" , "Lady", "Female"),
labels = c("Male", "Male", "Female", "Female")))
#> [1] Male Male Male Female Female
#> Levels: Male Female
## Using addNA()
Month <- airquality$Month
table(addNA(Month))
table(addNA(Month, ifany = TRUE))'Data > Manage variables in active data set' 카테고리의 다른 글
| 9. Drop unused factor levels... (0) | 2022.02.10 |
|---|---|
| 8. Reorder factor levels... (0) | 2022.02.10 |
| 12. Delete variables from data set... (0) | 2020.03.21 |
| 11. Rename variables... (0) | 2020.03.21 |
| 7. Bin a numeric variable... (0) | 2020.03.21 |


