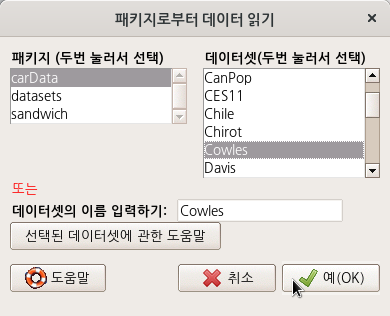
datasets::warpbreaks()

data(warpbreaks, package="datasets") # 데이터셋 불러오기
help("warpbreaks") # 데이터셋 도움말 보기
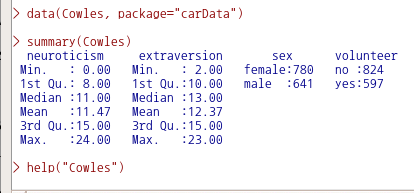
summary(warpbreaks) # 데이터셋 통계 요약 보기
R Commander 화면 상단 우측에 있는 <데이터셋 보기> 버튼을 누른다. 아래와 같이 warpbreaks 데이터셋의 내부 구성을 볼 수 있다.

| warpbreaks {datasets} | R Documentation |
The Number of Breaks in Yarn during Weaving
Description
This data set gives the number of warp breaks per loom, where a loom corresponds to a fixed length of yarn.
Usage
warpbreaksFormat
A data frame with 54 observations on 3 variables.
| [,1] | breaks | numeric | The number of breaks |
| [,2] | wool | factor | The type of wool (A or B) |
| [,3] | tension | factor | The level of tension (L, M, H) |
There are measurements on 9 looms for each of the six types of warp (AL, AM, AH, BL, BM, BH).
Source
Tippett, L. H. C. (1950) Technological Applications of Statistics. Wiley. Page 106.
References
Tukey, J. W. (1977) Exploratory Data Analysis. Addison-Wesley.
McNeil, D. R. (1977) Interactive Data Analysis. Wiley.
See Also
xtabs for ways to display these data as a table.
Examples
require(stats); require(graphics)
summary(warpbreaks)
opar <- par(mfrow = c(1, 2), oma = c(0, 0, 1.1, 0))
plot(breaks ~ tension, data = warpbreaks, col = "lightgray",
varwidth = TRUE, subset = wool == "A", main = "Wool A")
plot(breaks ~ tension, data = warpbreaks, col = "lightgray",
varwidth = TRUE, subset = wool == "B", main = "Wool B")
mtext("warpbreaks data", side = 3, outer = TRUE)
par(opar)
summary(fm1 <- lm(breaks ~ wool*tension, data = warpbreaks))
anova(fm1)
[Package datasets version 4.0.4 Index]
'Dataset_info > warpbreaks' 카테고리의 다른 글
| warpbreaks 데이터셋 예제 (0) | 2022.06.25 |
|---|