분석을 앞두고 결측자료(결측데이터)를 어떻게 처리할 것인가가 중요한 경우도 많다. 결측데이터(결측자료)를 제거하는 기능이다. 결측자료가 많은 상황에서 모든 결측자료를 제거하면 사례의 수가 크게 감소하는 위험이 발생하기도 한다. 그래서 결측자료를 제거하기전에 분석에 필요한 하위셋을 먼저 만드는 것을 추천한다.
Linux 사례 (MX 21)
분석에 사용될 하위셋을 만들고, 결측자료를 제거할 때 <모든 변수 포함하기>/<변수 (하나 이상 선택)>을 결정해야 한다. 선택 이후 새로운 데이터셋 이름을 지정하는 것을 추천한다.
Windows 사례
출력창의 정보를 보면 na.omit() 함수가 사용된다. 결측치 4개가 제거된다. 행의 수가 102개에서 98개로 축소된다.
Windows 사례
새로운데이터셋 <- na.omit(활성데이터셋)
만약, 데이터셋에서 분석에 포함되는 변수 선정이 분명하고, 선정된 변수들 안에 있을 수 있는 결측치를 제거하고자 할 때는 <모든 변수 포함하기> 대신 <변수 (하나 이상 선택) >에서 변수들을 선택하면 된다.
?na.omit # base 패키지의 na.omit 도움말 보기
DF <- data.frame(x = c(1, 2, 3), y = c(0, 10, NA))
na.omit(DF)
m <- as.matrix(DF)
na.omit(m)
stopifnot(all(na.omit(1:3) == 1:3)) # does not affect objects with no NA's
try(na.fail(DF)) #> Error: missing values in ...
options("na.action")
데이터 > 활성 데이터셋 > 활성 데이터셋의 누적변수... Data > Active data set > Stack variables in active data set...
Linux 사례 (MX 21)
변수에는 수치형 변수와 요인(범주)형 변수, 문자형 변수 등이 있다. 수치형 변수이름을 요인화시켜 데이터셋을 재배열화시키는 것이 이 기능이다. <누적 데이터셋 이름>, <변수 이름>, <요인 이름> 에 미리 추천된 내용이 입력되어 있으나 사용자가 임의로 새롭게 지정할 수 있다. 일반적으로 변수이름을 바꾸기도 한다.
Windows 사례
재배열된 데이터셋에서 선택된 수치형 변수들은 요인화된 새로운 변수의 요인 이름으로 변하기 때문에 일반적으로 데이터셋의 사례가 크게 증가한다. 변수를 2개 선택하면 2배, 3개 선택하면 3배로 행의 길이가 길어진다. 위의 화면에서 변수 두개, education, income을 선택하고 나머지를 기본설정 그대로 유지하고 예(OK) 버튼을 누른다. 아래 화면처럼 변경 사항들이 등장한다. R 아이콘 옆에<데이터셋: StackedData>으로 활성 데이터셋이 변경되고, 알림글에 StackedData 데이터셋의 행과 열 정보가 등장한다.
?stack # utils 패키지의 stack 도움말 보기
require(stats)
formula(PlantGrowth) # check the default formula
pg <- unstack(PlantGrowth) # unstack according to this formula
pg
stack(pg) # now put it back together
stack(pg, select = -ctrl) # omitting one vector
데이터 > 활성 데이터셋 > 활성 데이터셋에서 행(rows) 제거하기... Data > Active data set > Remove row(s) from active data set...
Linux 사례 (MX 21)
활성 데이터셋에서 행을 제거하는 기능이다. 대화창이 열리면 사용자는 제거할 행의 정보를 알고 있는 상황에서 제거를 위한 행을 지정해야 한다. 색인 또는 행의 이름, 행의 일련번호 등을 알고 있어야 한다. 초보자에게는 쉽지 않은 기능이다.
Linux 사례 (Ubuntu 18.04)
예를 들어 100개의 사례가 일련번호로 지정되어 있다고 가정하자. 1번을 제거하기 위해서는 1을 입력하면 되고, 90번을 제거하기 위해서는 90을 입력하면 되고, 11번에서 20번까지 묶음을 제거하려면 11:20을 입력하면 된다. 만약 1, 11:20, 90을 한꺼번에 제거하려면 어떻해야할까. 1, 11:20, 90을 넣으면 오류문이 출력된다. 오류문을 살펴보면 쉼표(,)가 두 개 찍혀있는 것을 보게될 것이다. 1 11:20 90 으로 입력하면 작동할 것이다. 빈공간(스페이스)이 쉼표 기능을 한다.
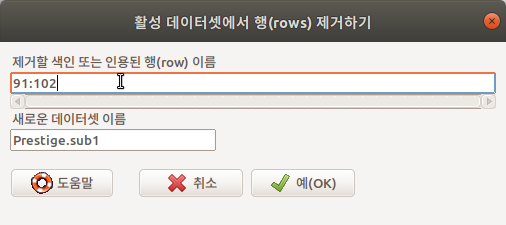
예를 들어, Prestige 데이터셋은 6개의 변수와 102개의 사례가 있다. 91번부터 102번까지 12개의 사례를 제거하려고 한다. 다음과 같이 '91:102'를 <제거할 색인 또는 인용된 행(row) 이름> 에 입력한다.
Linux 사례 (Ubuntu 18.04)
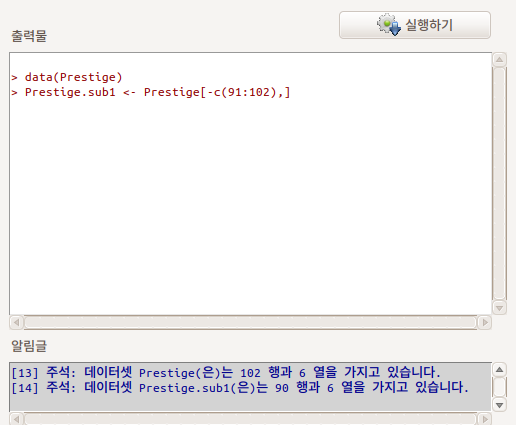
출력창을 살펴보자. 다음과 같은 형식이다: 새로운데이터셋 <- 활성데이터셋[-c(제거시작행번호: 제거마지막행번호), ] 출력창 아래를 보면 알림글에서 사례의 갯수가 90개로 바뀌었음을 알 수 있다.
Linux 사례 (Ubuntu 18.04)
이렇게 제거할 행을 지정하면, 행의 일련번호가 바뀌는 것을 기억해야 한다. <새로운 데이터셋 이름>으로 데이터셋을 지정하는 것이 필요하다. 이름을 입력하지 않으면 기존 활성 데이터셋 이름을 덮어쓰는 위험이 있다.
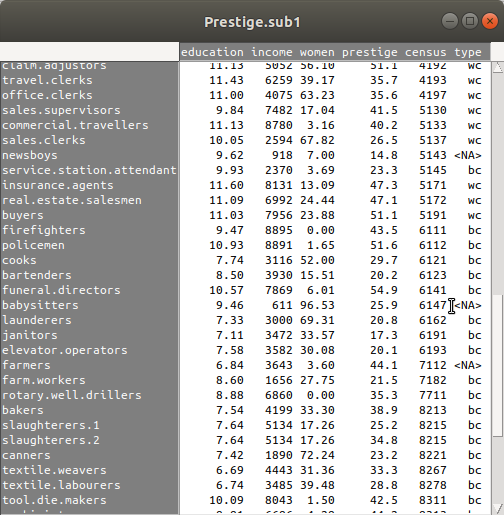
한편, Prestige 데이터셋의 type 변수에 값이 입력되지 않은 것이 있다. newsboys, babysitters, farmers 라는 사례명을 가진 행의 type 변수 칸에는 <NA> 으로 되어있다.
Linux 사례 (Ubuntu 18.04)
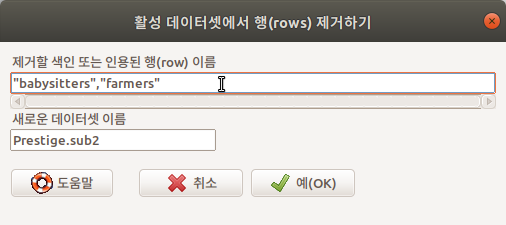
babysitters, farmers라는 두개의 사례를 제거해보자. 이 경우는 앞서서 행의 번호를 입력한 것과 달리 "babysitters", "farmers"라고 입력해야 한다.
Linux 사례 (Ubuntu 18.04)
다소 생소하고 복잡해 보이는 방식으로 명령문을 입력해야 한다. 논리적으로 보면, 데이터셋의 사례 이름들 중에서 제거하고자 하는 사례 이름들을 찾아서 데이터셋에서 삭제하라는 뜻이다. 새로운데이터셋 <- 활성데이터셋[!(rownames(활성데이터셋) %in% c("제거사례이름1", "제거사례이름2")), ]
Prestige.sub1 데이터셋에서 babysitters, farmers 두개의 사례를 제거했기 때문에, 알림글의 지시문을 보면 사례수는 90개에서 88개로 줄어들었음을 확인할 수 있다.
Linux 사례 (MX 21)
?Extract.data.frame # base 패키지의 Extract.data.frame 도움말 보기
sw <- swiss[1:5, 1:4] # select a manageable subset
sw[1:3] # select columns
sw[, 1:3] # same
sw[4:5, 1:3] # select rows and columns
sw[1] # a one-column data frame
sw[, 1, drop = FALSE] # the same
sw[, 1] # a (unnamed) vector
sw[[1]] # the same
sw$Fert # the same (possibly w/ warning, see ?Extract)
sw[1,] # a one-row data frame
sw[1,, drop = TRUE] # a list
sw["C", ] # partially matches
sw[match("C", row.names(sw)), ] # no exact match
try(sw[, "Ferti"]) # column names must match exactly
swiss[ c(1, 1:2), ] # duplicate row, unique row names are created
sw[sw <= 6] <- 6 # logical matrix indexing
sw
## adding a column
sw["new1"] <- LETTERS[1:5] # adds a character column
sw[["new2"]] <- letters[1:5] # ditto
sw[, "new3"] <- LETTERS[1:5] # ditto
sw$new4 <- 1:5
sapply(sw, class)
sw$new # -> NULL: no unique partial match
sw$new4 <- NULL # delete the column
sw
sw[6:8] <- list(letters[10:14], NULL, aa = 1:5)
# update col. 6, delete 7, append
sw
## matrices in a data frame
A <- data.frame(x = 1:3, y = I(matrix(4:9, 3, 2)),
z = I(matrix(letters[1:9], 3, 3)))
A[1:3, "y"] # a matrix
A[1:3, "z"] # a matrix
A[, "y"] # a matrix
stopifnot(identical(colnames(A), c("x", "y", "z")), ncol(A) == 3L,
identical(A[,"y"], A[1:3, "y"]),
inherits (A[,"y"], "AsIs"))
## keeping special attributes: use a class with a
## "as.data.frame" and "[" method;
## "avector" := vector that keeps attributes. Could provide a constructor
## avector <- function(x) { class(x) <- c("avector", class(x)); x }
as.data.frame.avector <- as.data.frame.vector
`[.avector` <- function(x,i,...) {
r <- NextMethod("[")
mostattributes(r) <- attributes(x)
r
}
d <- data.frame(i = 0:7, f = gl(2,4),
u = structure(11:18, unit = "kg", class = "avector"))
str(d[2:4, -1]) # 'u' keeps its "unit"
데이터 > 활성 데이터셋 > 활성 데이터셋의 합계 변수... Data > Active data set > Aggregate variables in active data set...
Linux 사례 (MX 21)
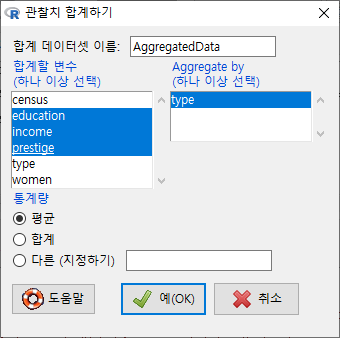
데이터셋의 변수에는 수치형과 범주형, 문자형 등이 있다. 범주형 변수, 보통 R에서 factor(요인)형이라 부르는 변수를 기준으로 수치형 값들을 묶을 수 있다. 이 기능을 이해하기 위해서는 사용자가 수치형/요인형/문자형 등의 데이터유형에 대하여 알고 있어야 한다.
대화창에서 <Aggregate by (하나 이상 선택) > 에 등장하는 변수는 요인형 변수이며, 이 변수의 개별 요인형 사례를 기준으로 나머지 변수들의 정보가 묶이게 된다. 아래 화면의 type 변수는 요인형 변수이며, 나머지 변수는 수치형 변수인 것이다. <평균/합/다른 (지정하기)>의 옵션에서 선택할 수 있다. <합계 데이터셋 이름>은 'AggregateData'로 지정되어 있으나, 사용자가 임의로 바꿔서 사용할 수 있다.
Windows 사례
예(OK)를 누르면, AggregatedData라는 데이터셋이 생성된다. <데이터셋 보기> 를 통해서 내부를 살펴보면, 직업 유형 (type)별로 직업의 권위에 대한 인식(prestige)의 평균 값이 보인다.
Windows 사례
하나 이상의 수치형 변수를 선택해보자. Prestige 데이터셋에서 세개의 변수, education, income, prestige 를 선택하고 예(OK) 버튼을 누르자.
Windows 사례
<데이터셋 보기> 버튼을 눌러 AggregatedData 내부를 살펴보면, 직업 유형 (type) 별로, 교육 연수(education), 연 수입(income), 권위 인식(prestige)의 평균 값이 확인할 수 있다.
Windows 사례
아래 입력창은 두개의 합계 데이터셋을 만든다. AggregatedData, AggregatedData1인데, aggregate() 함수가 사용되는 것을 알 수 있다.
?aggregate # stats 패키지의 aggregate 도움말 보기
## Compute the averages for the variables in 'state.x77', grouped
## according to the region (Northeast, South, North Central, West) that
## each state belongs to.
aggregate(state.x77, list(Region = state.region), mean)
## Compute the averages according to region and the occurrence of more
## than 130 days of frost.
aggregate(state.x77,
list(Region = state.region,
Cold = state.x77[,"Frost"] > 130),
mean)
## (Note that no state in 'South' is THAT cold.)
## example with character variables and NAs
testDF <- data.frame(v1 = c(1,3,5,7,8,3,5,NA,4,5,7,9),
v2 = c(11,33,55,77,88,33,55,NA,44,55,77,99) )
by1 <- c("red", "blue", 1, 2, NA, "big", 1, 2, "red", 1, NA, 12)
by2 <- c("wet", "dry", 99, 95, NA, "damp", 95, 99, "red", 99, NA, NA)
aggregate(x = testDF, by = list(by1, by2), FUN = "mean")
# and if you want to treat NAs as a group
fby1 <- factor(by1, exclude = "")
fby2 <- factor(by2, exclude = "")
aggregate(x = testDF, by = list(fby1, fby2), FUN = "mean")
## Formulas, one ~ one, one ~ many, many ~ one, and many ~ many:
aggregate(weight ~ feed, data = chickwts, mean)
aggregate(breaks ~ wool + tension, data = warpbreaks, mean)
aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, mean)
aggregate(cbind(ncases, ncontrols) ~ alcgp + tobgp, data = esoph, sum)
## Dot notation:
aggregate(. ~ Species, data = iris, mean)
aggregate(len ~ ., data = ToothGrowth, mean)
## Often followed by xtabs():
ag <- aggregate(len ~ ., data = ToothGrowth, mean)
xtabs(len ~ ., data = ag)
## Compute the average annual approval ratings for American presidents.
aggregate(presidents, nfrequency = 1, FUN = mean)
## Give the summer less weight.
aggregate(presidents, nfrequency = 1,
FUN = weighted.mean, w = c(1, 1, 0.5, 1))
데이터 > 활성 데이터셋 > 활성 데이터셋 정렬하기... Data > Active Data set > Sort active data set...
데이터셋의 행의 순서를 조정할 수 있다. 이 기능은 특정 변수(들)을 선택하여 증가/감소 등의 순서로 행의 순서를 조정하는 기능이다. 보통 데이터셋에서 필요 변수(사례들)를 선택하여 하위셋을 만들고, 이후 내용적인 이해를 위하여 이 기능을 사용한다.
Linux 사례 (MX 21)
새롭게 정렬할 변수(들)을 선택하고, 증가/감소 등의 방향을 결정한 후, 새로운 데이터셋의 이름을 입력하게 된다. 입력하지 않으면 현재 사용중인 데이터셋의 이름을 덮어쓰는 위험이 있다. 경험적으로 나의 경우는 데이터셋.sort1, 데이터셋.sort2 등으로 새로운 데이터셋의 이름을 정한다.
직종의 권위에 대한 인식의 높낮이를 기준으로 자료를 정렬해보자. prestige 변수를 선택하고, <방향 정렬하기>에서 감소하기를 선택하고, <새로운 데이터셋 이름>에서 Prestige.sort1 이라고 입력한다.
Windows 사례
출력창에 함수의 용례를 확인할 수 있다. 정렬의 기준 변수를 선택하고, order() 함수와 높은 순서로 정렬하는 인자인 'decreasing=TRUE'를 사용한다. 새로운데이터셋 <- with(활성데이터셋, 활성데이터셋[order(기준변수이름, decreasing=TRUE), ]) 등의 함수 용례를 보게된다:
Windows 사례
R Commander의 상단에 있는 R 아이콘 옆에 <데이터셋: Prestige.sort1>이라고 활성데이텃 이름이 바뀐 것을 보게될 것이다. 어떻게 데이터셋이 정렬되었는지 보려면 <데이터셋 보기> 버튼을 누른다.
Windows 사례
두개 이상의 변수를 선택할 경우는 추가 대화창에서 정렬 키의 순서를 결정할 수 있다. 직업의 권위가 높은 순서로, 교육 연수가 높은 순서로 정렬해보자.
Windwos 사례
기준(key)이 되는 변수가 하나일 때와 달리, 둘 이상의 변수를 선택할 때는 <정렬 키 다시 순서정하기> 창이 등장한다. 앞서 만든 기준을 위하여 prestige를 1로, education을 2로 순서를 바꿔보자.
Windows 사례
R Commander의 화면에서 활성 데이터셋이 Prestige.sort2로 바뀐다. 그리고 출력창에 새로운 함수 용례가 다음과 같이 등장할 것이다. 새로운데이터셋 <- with(활성데이터셋, 활성데이터셋[order(기준변수1이름, 기준변수2이름, decreasing=TRUE), ])
Windows 사례
<데이터셋 보기>를 눌러서 정렬의 결과를 살펴보자. prestige 변수의 사례 값이 68.8인 것이 두개 있다. mining.engineers, gov.administrators 인데, 둘째 기준변수인 education의 높은 순서로 정렬되어 있다. 각각 14.64, 13.11 이다. 앞서 기준변수가 prestige 하나였던 데이터셋과 정렬을 비교해보자. 상단의 Prestige.sort1 데이터셋에는 gov.administrators가 mining.engineers보다 위에 있는 것을 확인할 수 있다.
Windows 사례
?order # base 패키지에 있는 order 도움말 보기
require(stats)
(ii <- order(x <- c(1,1,3:1,1:4,3), y <- c(9,9:1), z <- c(2,1:9)))
## 6 5 2 1 7 4 10 8 3 9
rbind(x, y, z)[,ii] # shows the reordering (ties via 2nd & 3rd arg)
## Suppose we wanted descending order on y.
## A simple solution for numeric 'y' is
rbind(x, y, z)[, order(x, -y, z)]
## More generally we can make use of xtfrm
cy <- as.character(y)
rbind(x, y, z)[, order(x, -xtfrm(cy), z)]
## The radix sort supports multiple 'decreasing' values:
rbind(x, y, z)[, order(x, cy, z, decreasing = c(FALSE, TRUE, FALSE),
method="radix")]
## Sorting data frames:
dd <- transform(data.frame(x, y, z),
z = factor(z, labels = LETTERS[9:1]))
## Either as above {for factor 'z' : using internal coding}:
dd[ order(x, -y, z), ]
## or along 1st column, ties along 2nd, ... *arbitrary* no.{columns}:
dd[ do.call(order, dd), ]
set.seed(1) # reproducible example:
d4 <- data.frame(x = round( rnorm(100)), y = round(10*runif(100)),
z = round( 8*rnorm(100)), u = round(50*runif(100)))
(d4s <- d4[ do.call(order, d4), ])
(i <- which(diff(d4s[, 3]) == 0))
# in 2 places, needed 3 cols to break ties:
d4s[ rbind(i, i+1), ]
## rearrange matched vectors so that the first is in ascending order
x <- c(5:1, 6:8, 12:9)
y <- (x - 5)^2
o <- order(x)
rbind(x[o], y[o])
## tests of na.last
a <- c(4, 3, 2, NA, 1)
b <- c(4, NA, 2, 7, 1)
z <- cbind(a, b)
(o <- order(a, b)); z[o, ]
(o <- order(a, b, na.last = FALSE)); z[o, ]
(o <- order(a, b, na.last = NA)); z[o, ]
## speed examples on an average laptop for long vectors:
## factor/small-valued integers:
x <- factor(sample(letters, 1e7, replace = TRUE))
system.time(o <- sort.list(x, method = "quick", na.last = NA)) # 0.1 sec
stopifnot(!is.unsorted(x[o]))
system.time(o <- sort.list(x, method = "radix")) # 0.05 sec, 2X faster
stopifnot(!is.unsorted(x[o]))
## large-valued integers:
xx <- sample(1:200000, 1e7, replace = TRUE)
system.time(o <- sort.list(xx, method = "quick", na.last = NA)) # 0.3 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.2 sec
## character vectors:
xx <- sample(state.name, 1e6, replace = TRUE)
system.time(o <- sort.list(xx, method = "shell")) # 2 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.007 sec, 300X faster
## double vectors:
xx <- rnorm(1e6)
system.time(o <- sort.list(xx, method = "shell")) # 0.4 sec
system.time(o <- sort.list(xx, method = "quick", na.last = NA)) # 0.1 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.05 sec, 2X faster
Data > Active Data set > Subset active data set...
데이터셋에 담긴 모든 변수를 분석에 활용하는 경우는 거의 없다. 분석을 위하여 데이터셋의 일부를 사용하는 경우가 일반적이다. 분석에 필요한 변수집단을 선택하여 하위셋을 만드는 기능이다.
Linux 사례 (MX 21)
변수집단을 선택할 경우는 <모든 변수 사용하기>에 기본지정된 옵션을 해제해야 한다. 물론 변수일부를 선택하는 것과 별개로 사례값(행) 일부를 선택할 수도 있다. 이 경우는 사용자가 직접 <하위셋 표현식>에 스크립트를 입력해야 한다. 초보자는 당황할 수 있다.
Windows 사례
변수 일부나 행 일부를 선택한 후에는 새로운 데이터셋 이름을 입력해야 한다. 그렇지 않으면 기존 데이터셋 이름을 덮어쓰는 위험이 발생한다. 경험적으로 나는 하위데이터셋 이름은 데이터셋.sub1, 데이터셋.sub2 또는 sub1.데이터셋, sub2.데이터셋 등으로 사용하여 원데이터의 이름을 유지시킨다.
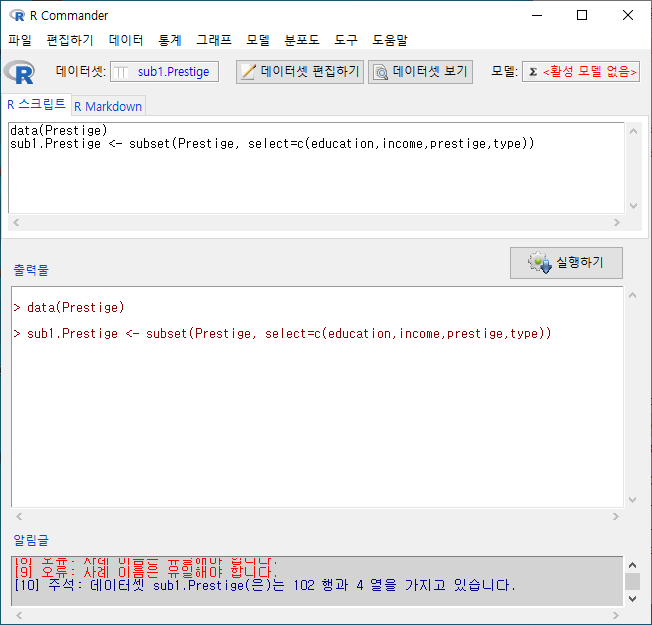
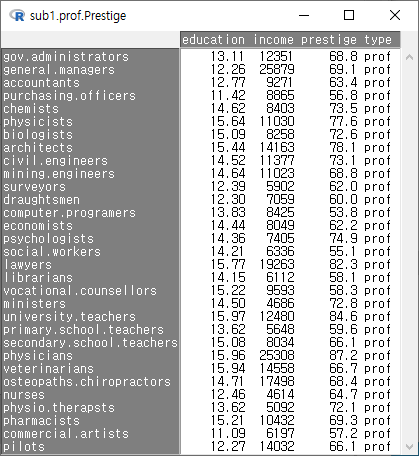
Prestige 데이터셋에서 변수 네개를 선택한다고 하자. education, income, prestige, type 변수를 선택하고, sub1.Prestige라고 데이터셋의 이름을 붙였다고 하자.
Windows 사례
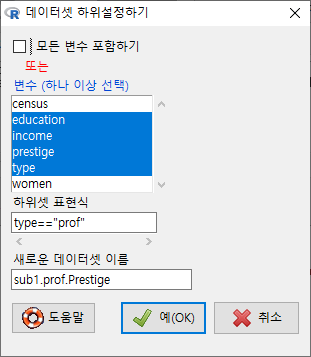
그런데, type 변수에는 "prof", "bc", "wc"라는 요인(factor)형 정보가 담겨있다. 이 중에서 전문직(prof)에 관한 데이터의 정보만 추출하려면 다음과 같이 조건을 지정해야 한다.
Windows 사례
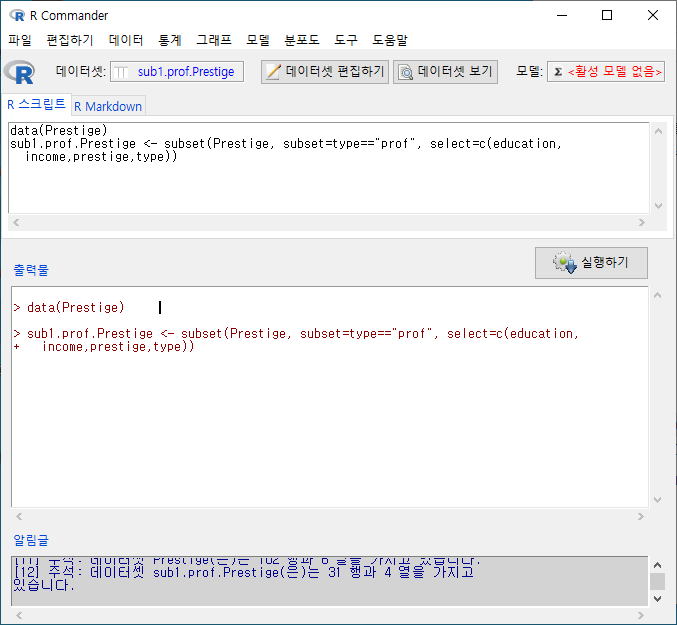
다음 화면의 입력창, 출력창, 알림글을 살펴보라. 활성 데이터셋의 이름이 sub1.prof.Prestige라고 바뀌었고, subset()의 인자가 추가되었으며, sub1.prof.Prestige 데이터셋의 행과 열 정보를 찾을 수 있다:
Windows 사례Windows 사례
subset(데이터셋이름, subset=조건, select=선택된변수목록)
?subset # base 패키지의 subset 도움말 보기
subset(airquality, Temp > 80, select = c(Ozone, Temp))
subset(airquality, Day == 1, select = -Temp)
subset(airquality, select = Ozone:Wind)
with(airquality, subset(Ozone, Temp > 80))
## sometimes requiring a logical 'subset' argument is a nuisance
nm <- rownames(state.x77)
start_with_M <- nm %in% grep("^M", nm, value = TRUE)
subset(state.x77, start_with_M, Illiteracy:Murder)
# but in recent versions of R this can simply be
subset(state.x77, grepl("^M", nm), Illiteracy:Murder)
활성 데이터셋으로 사용되는 데이터프레임은 행과 열을 갖는다. 변수이름이 열을 대표한다. 행의 경우, 일련번호로 사례를 대표하기도하고 고유한 이름을 붙이기도 한다. 이 기능은 행의 이름을 지정하는 것이다.
그런데, 이 기능을 사용하기 위해서는 R의 특징을 알아야 한다. 첫째, 사례 이름은 유일해야 한다. 동일한 행의 이름을 넣을 수 없다는 것이다. 이 원칙은 행의 이름으로 사용하기 위해서 변수들에서 하나를 선택해야하는 이 기능 <사례 이름 정하기>에서 많은 변수들이 이 원칙을 위배하기 때문에 오류문을 생산하는 경우가 흔하다. 행이름은 흔히 key 값이라 부르는 고유성을 가져야 하는데, 이 고유성이 어느 변수의 사례값에서 발견되기는 쉽지 않다.
<사례 이름 설정하기> 메뉴창에서, Prestige의 어떤 변수를 선택하더라도 알림글에 '오류: 사례 이름은 유일해야 합니다.'는 메세지를 볼 것이다. 숫자 형태의 일련번호 또는 개별화된 문자형 사례 이름에는 중복되는 이름을 넣을 수 없다는 뜻이다.
Windows 사례
Prestige 데이터셋의 변수이름은 아래와 같이 문자형 정보를 담고 있다. 만약 숫자 형태의 일련번호가 있었다면, 직업 이름을 담고 있는 변수의 사례들을 행 이름으로 바꿀 수 있었을 것이다.
Windows 사례
row.names(데이터셋이름)
?row.names # base 패키지의 row.names 도움말 보기
## To illustrate the note:
df <- data.frame(x = c(TRUE, FALSE, NA, NA), y = c(12, 34, 56, 78))
row.names(df) <- 1 : 4
attr(df, "row.names")
deparse(df)
## (Compact storage, not regarded as automatic.)
row.names(df) <- NULL
attr(df, "row.names")
deparse(df)
## (Compact storage, regarded as automatic.)
Data > Active data set > Variables in active data set
활성 데이터셋으로 불러온 데이터프레임에는 사례값들을 가지는 변수가 있을 것이다. 변수이름을 목록화시켜 보여주는 기능이다. 예제용 데이터셋은 핵심적인 목적을 위하여 정제된 경우가 대부분이기 때문에 이 기능이 큰 효과를 가지지 않는다. 하지만, 백 개 이상의 변수를 가진 데이터들도 흔한 상황에서 분석을 위한 데이터셋을 불러온 경우, 그리고 변수들이 많은 경우, 이 기능은 효과적으로 사용될 수 있다.
Linux 사례 (MX 21)
활성 데이터셋에 있는 변수들의 목록이 출력된다. Prestige 데이터셋에는 있는 변수 목록은 다음과 같다:
메모리에 올려진 데이터셋으로 작업하는 경우, 변수와 사례를 추가/삭제하는 경우가 빈번하게 발생한다. 줄여 말하면, 벡터를 만들거나 삭제할 수 있다. 이 경우, 작업이 진행된 객체의 '현재' 정보가 필요한 경우가 있다. 객체의 행과 열, 변수와 사례의 갯수를 업데이터해서 메세지로 알려준다.