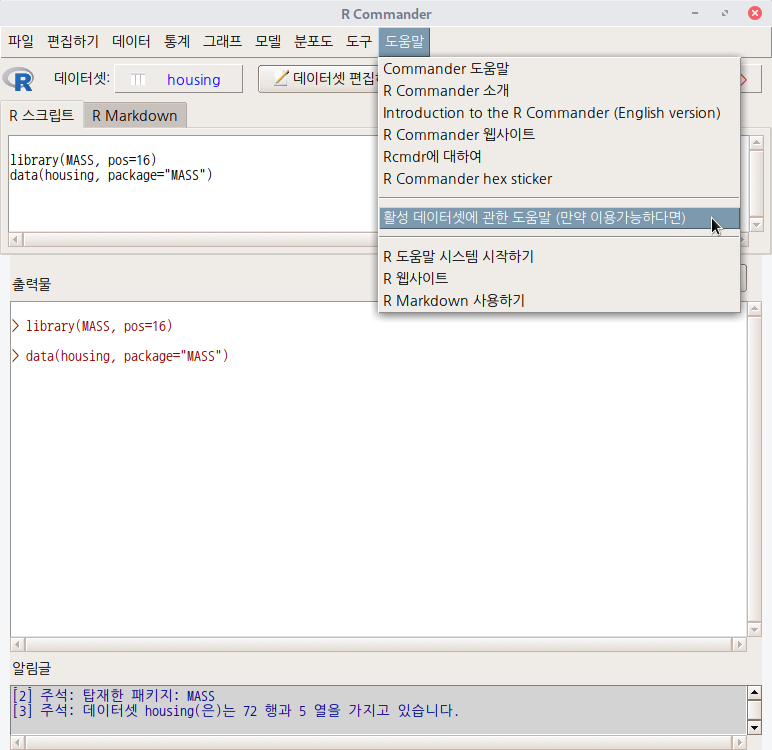
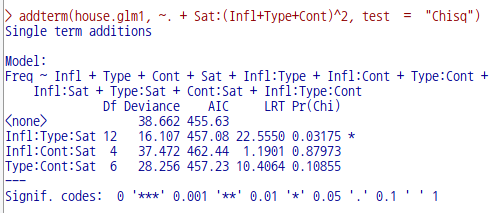
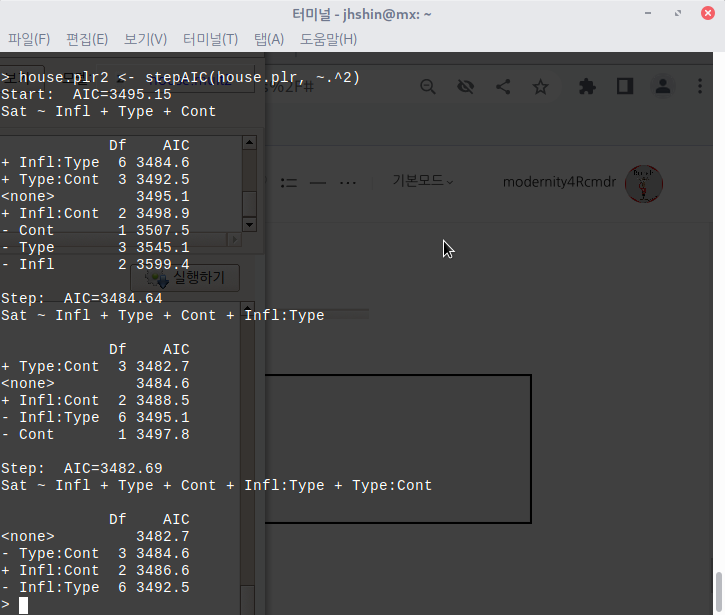
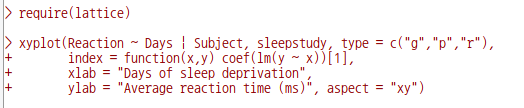
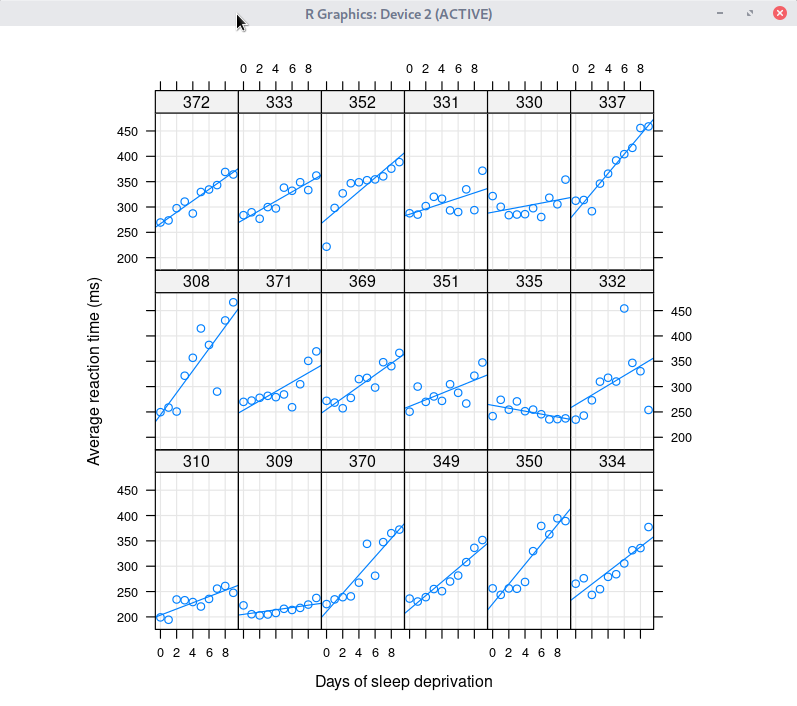
R에는 많은 패키지가 있으며, 그 패키지에는 많은 경우 데이터셋을 포함하고 있다. 그 데이터셋에 대한 도움말을 볼 수 있는 기능이다. 생각해보라. 예제 데이터셋을 통하여 함수를 연습하는데, 데이터셋의 특성을 알지 못한다면 분석과 시각화에 필요한 통찰력을 얻을 수 있겠는가.
위의 화면은 MASS 패키지가 적재되었고, 또 그 안에 포함된 housing 이라는 데이터셋이 활성화된 상태에서 '도움말 > 활성 데이터셋에 관한 도움말 (만약 이용가능하다면)' 메뉴 기능을 이용할 수 있다는 것이다. 해당 메뉴를 선택하면, 새로운 웹 브라우저 창이 등장하면서, 활성 데이터셋의 도움말이 제공될 것이다.
Linux 사례 (MX 21)
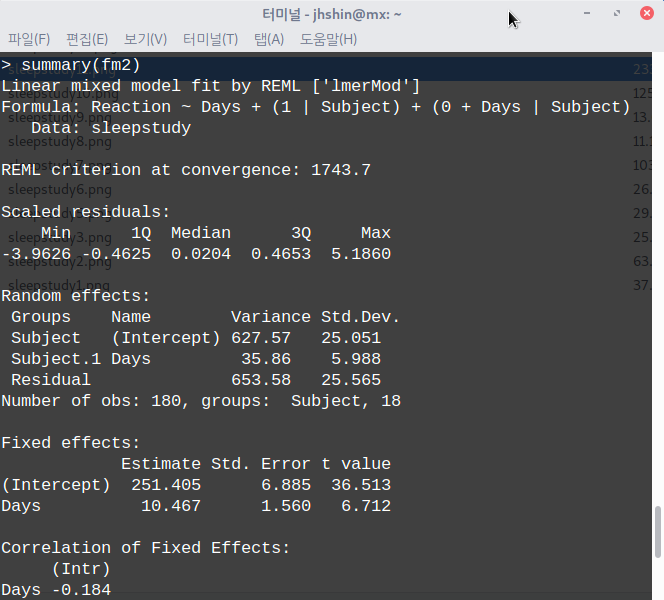
help("housing") # housing 데이터셋 도움말 보기
?housing # housing 데이터셋 도움말 보기 (? 활용)
?swiss # swiss 데이터셋 도움말 보기
# 아래는 example(swiss) 입니다.
require(stats); require(graphics)
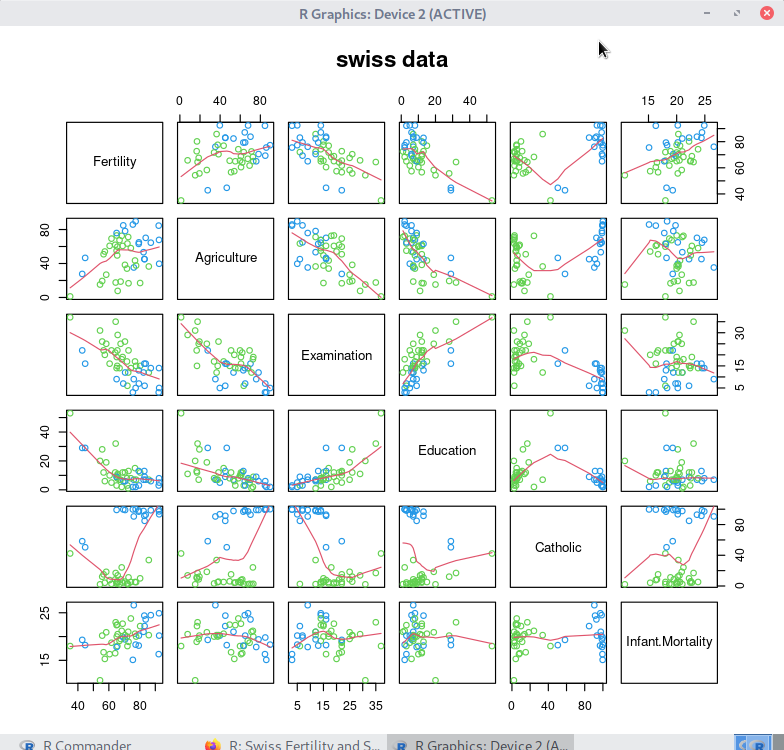
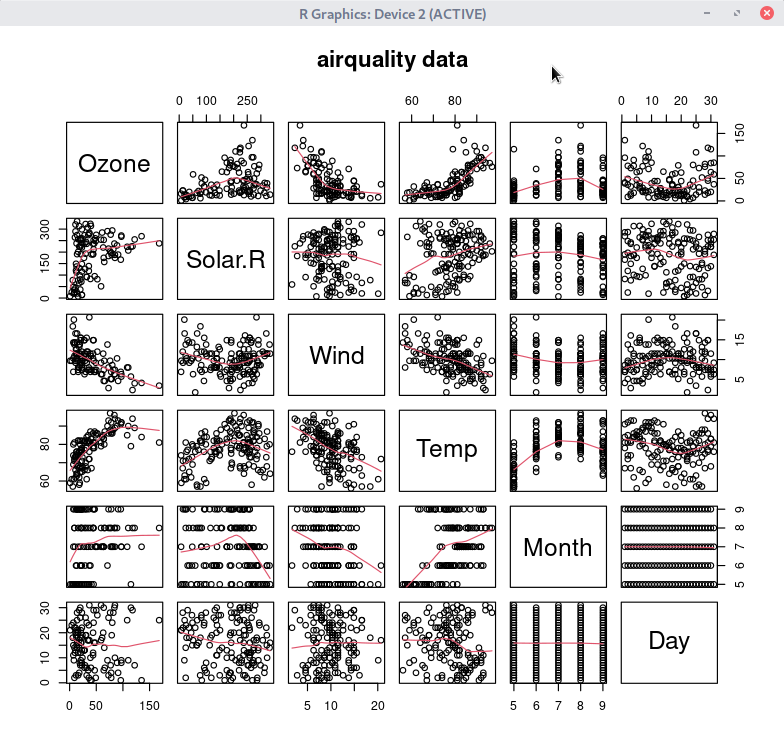
pairs(swiss, panel = panel.smooth, main = "swiss data",
col = 3 + (swiss$Catholic > 50))
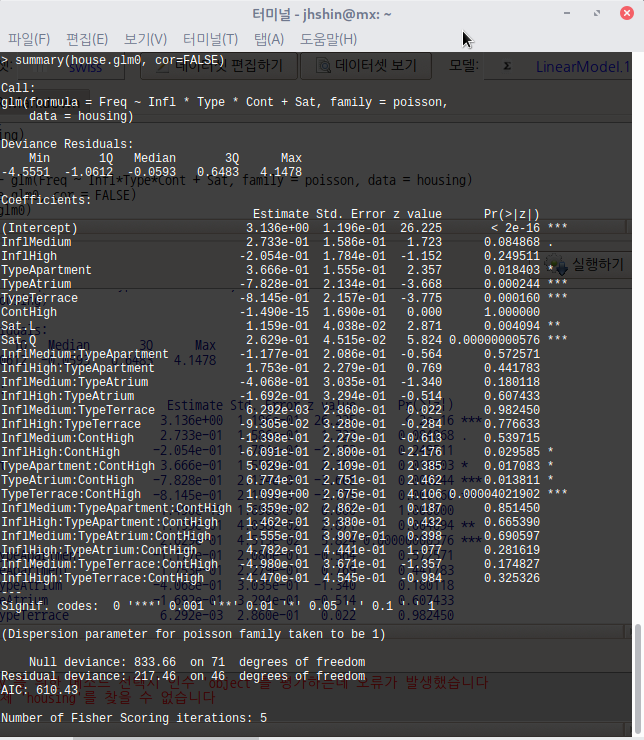
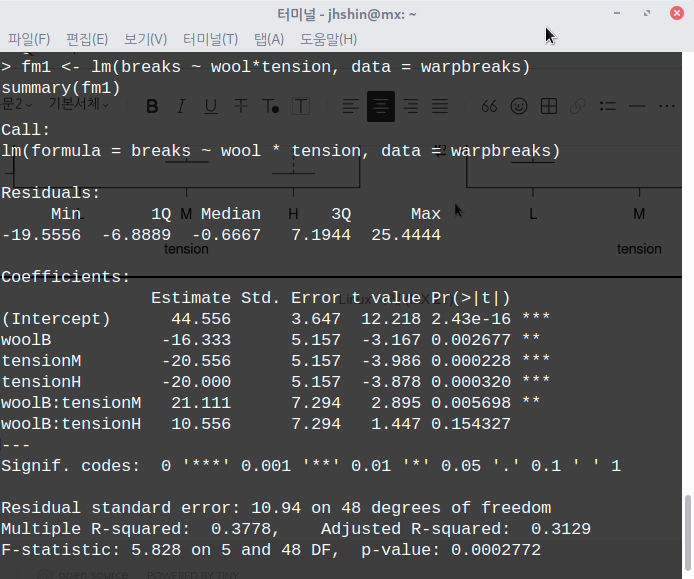
summary(lm(Fertility ~ . , data = swiss))
linux 사례 (MX 21)
pairs(swiss, panel = panel.smooth, main = "swiss data",
col = 3 + (swiss$Catholic > 50))
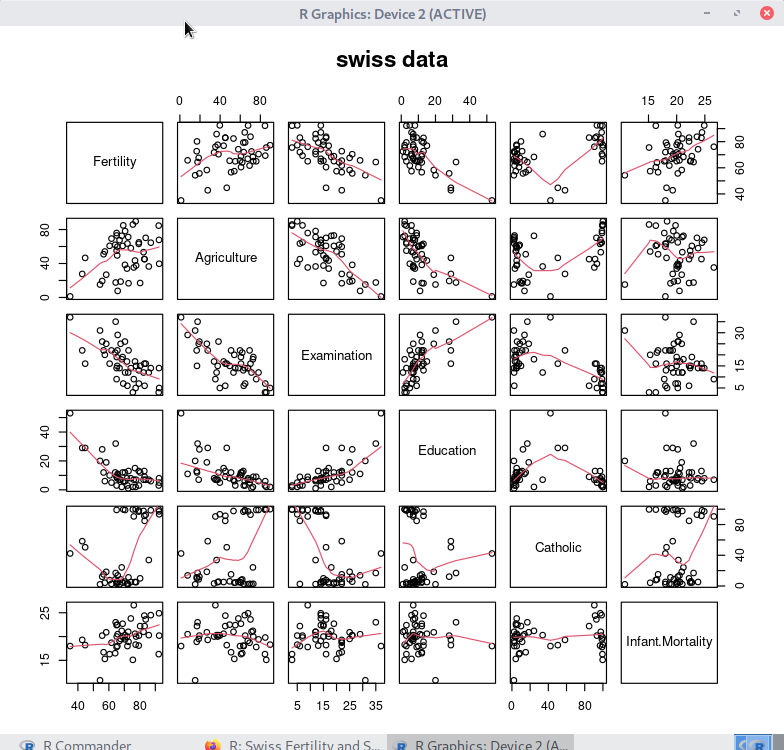
pairs(swiss, panel = panel.smooth, main = "swiss data") # 두 그래프를 비교해 보기
Linux 사례 (MX 21)Linux 사례 (MX 21)
LinearModel.1 <- lm(Fertility ~ . , data = swiss)
summary(LinearModel.1)