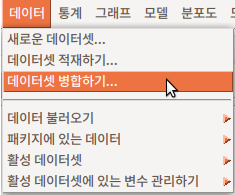
데이터 > 데이터 불러오기 > 텍스트 파일, 클립보드 또는 URL에서...
Data > Import data > from text file, clipboard, or URL...

개인적인 경험과 판단이지만, R에서 외부 데이터 파일을 불러오는 것을 초급자들은 너무 어려워한다. 쉽지 않다. 분석과 시각화 작업을 하기에 앞서서 자료 불러오기가 어려우니, 많은 사람이 쉬운 GUI 분석도구로 되돌아가려고 한다. read.table() 계열 함수가 어렵다.
R Commander는 이러한 불편함을 최소화하기 위하여 인자들을 쉽게 선정하도록 화면 구성이 되어있다. 하지만, 먼저 알아야할 것이 있다. R Commander에서 불러오는 객체, 다시말해 외부 데이터 파일로부터 불러올 대상은 반드시 데이터 프레임 형식을 취한다. 변수이름을 갖고, 엑셀과 같은 스프레드시트 형식으로 사례값들이 배열되어 있는 것만 GUI 메뉴로 작업할 수 있다. 만약, 데이터프레임 형식이 아니라면, 일반 콘솔 환경과 같은 조건에서 Command Line 작업을 해야한다.

- data set의 기본이름은 Dataset이다. 원하는 것으로 이름을 바꿀 수 있다. 가급적 영문을 추천한다. 행여 다른 시스템에서 파일이름의 호환문제를 겪을 수 있기 때문이다. (위의 메뉴 창에서는 Nations라고 데이터셋의 이름을 변경했다.)
- 결측치 표시는 NA가 기본설정이다.
- 외부 파일을 불러올지, 메모리(clipboard)에서 불러올지, 외부인터넷 경로에서 내려받을 지를 선택할 수 있다.
- 필드 구분자를 선택할 수 있다. 사실, 필드 구분자가 초급자에게는 어렵다. 빈 공백, commas, 세미 콜론, 탭 등이 사용되기 때문에 혼란스러울 수 있다. 일반적으로 .txt로 되어 있는 것은 빈 공백, .csv로 되어 있는 파일은 comman인 경우가 흔하다. 하지만, 정확한 내부 규칙이 없기 때문에 어려개를 번갈아 선택해봐야할 수 있다.
- Decimal-Point의 경우, 한국은 미국스타일의 Period[.]를 관행적으로 쓰기 때문에 기본설정을 따르면 된다.

Nations <- read.table("/home/jhshin/다운로드/Rcmdr/inst/etc/Nations.txt", header=TRUE,
stringsAsFactors=TRUE, sep="", na.strings="NA", dec=".", strip.white=TRUE)Nations라는 이름으로 불러온 데이터셋이 활성화되어 R Commander 에서 활용할 수 있는 환경이 시작된다.
사례를 하나 소개한다. libreOffice Calc에서 엑셀파일을 불러오고, 또 이것의 첫 시트를 clipboard에 복사하고, R Commander로 불러온다고 생각해보자.
- Locatioin of Data File에서 Clipboard를 선택하고,
- Field Separator에서 Tabs(탭)을 선택해야 한다. 기본설정을 바꿔야한다는 뜻이다.
한가지 유의해야할 것은 변수이름이 바뀌는 규칙이 있다는 점이다.
- R에서는 괄호를 변수이름에 넣을 수 없다. 앞뒤 괄호는 ..으로 바뀐다. '연락처(대표)'는 '연락처.대표.'로 바뀐다.
데이터 파일이 (어떤 규칙성에 의하여 성공적으로) 불러와지면, 상단의 R 아이콘 옆에 Data set:에 파란 색의 객체이름이 보인다. 기본설정이라면 Dataset이 될 것이다.
?read.table # utils 패키지의 read.table 도움말 보기
## using count.fields to handle unknown maximum number of fields
## when fill = TRUE
test1 <- c(1:5, "6,7", "8,9,10")
tf <- tempfile()
writeLines(test1, tf)
read.csv(tf, fill = TRUE) # 1 column
ncol <- max(count.fields(tf, sep = ","))
read.csv(tf, fill = TRUE, header = FALSE,
col.names = paste0("V", seq_len(ncol)))
unlink(tf)
## "Inline" data set, using text=
## Notice that leading and trailing empty lines are auto-trimmed
read.table(header = TRUE, text = "
a b
1 2
3 4
")
'Data > Import data' 카테고리의 다른 글
| from STATA data set... (0) | 2019.05.12 |
|---|---|
| from Minitab data set... (0) | 2019.05.12 |
| from SAS b7dat file... (0) | 2019.05.12 |
| from SAS xport file... (0) | 2019.05.12 |
| from SPSS data set... (0) | 2019.05.12 |