데이터 > 활성 데이터셋의 변수 관리하기 > 요인 수준 재정렬하기...
Data > Manage variables in active data set > Reorder factor levels...

carData 패키지의 Prestige 데이터셋을 이용해서 <요인 수준 재정렬하기> 기능을 사용해보자. Prestige 데이터셋에 있는 직업유형을 나타내는 type 변수는 bc, prof, wc라는 요인 수준을 갖고 있다. blue collar, white collar, professional 블루칼라, 화이트칼라, 전문직 등을 나타낸다. 그런데, bc, prof, wc는 순서가 있는 요인 수준이 아니다. 요인의 알파벳 순서대로 1, 2, 3 등이 부여된 요인 수준이다.
첫째로 bc, wc, prof로 수준의 순서를 바꿔보자. 먼저 type1으로 요인형 변수의 이름을 새롭게 정해보자.
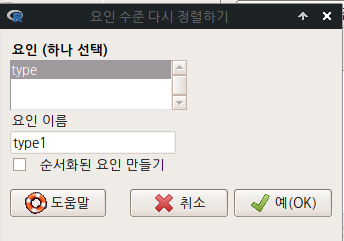
bc에 1, wc에 2, prof에 3을 넣는다.

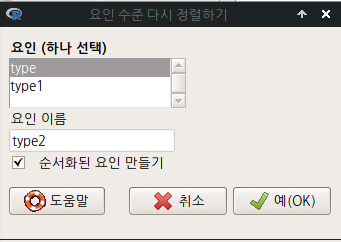
그렇다면, 둘째로 bc, wc, prof 순서를 정해놓고 각각 1, 2, 3을 지정해서 요인 수준을 정해보자. 정확히는 bc < wc < prof 순서를 정해놓고, 각각 1, 2, 3을 부여하는 것이다. type2라는 요인형 변수로 지정한다.

str() 함수를 이용하여, type, type1, type2 변수의 구조를 살펴보자. 그리고 factor() 함수의 용례를 다시 살펴보라. levels, ordered 라는 인자가 의미하는 것을 알게될 것이다.
Prestige$type1 <- with(Prestige, factor(type, levels=c('bc','wc','prof')))
Prestige$type2 <- with(Prestige, factor(type, levels=c('bc','wc','prof'), ordered=TRUE))
str(Prestige$type)
str(Prestige$type1)
str(Prestige$type2)
?factor # base 패키지의 factor 도움말 보기
(ff <- factor(substring("statistics", 1:10, 1:10), levels = letters))
as.integer(ff) # the internal codes
(f. <- factor(ff)) # drops the levels that do not occur
ff[, drop = TRUE] # the same, more transparently
factor(letters[1:20], labels = "letter")
class(ordered(4:1)) # "ordered", inheriting from "factor"
z <- factor(LETTERS[3:1], ordered = TRUE)
## and "relational" methods work:
stopifnot(sort(z)[c(1,3)] == range(z), min(z) < max(z))
## suppose you want "NA" as a level, and to allow missing values.
(x <- factor(c(1, 2, NA), exclude = NULL))
is.na(x)[2] <- TRUE
x # [1] 1 <NA> <NA>
is.na(x)
# [1] FALSE TRUE FALSE
## More rational, since R 3.4.0 :
factor(c(1:2, NA), exclude = "" ) # keeps <NA> , as
factor(c(1:2, NA), exclude = NULL) # always did
## exclude = <character>
z # ordered levels 'A < B < C'
factor(z, exclude = "C") # does exclude
factor(z, exclude = "B") # ditto
## Now, labels maybe duplicated:
## factor() with duplicated labels allowing to "merge levels"
x <- c("Man", "Male", "Man", "Lady", "Female")
## Map from 4 different values to only two levels:
(xf <- factor(x, levels = c("Male", "Man" , "Lady", "Female"),
labels = c("Male", "Male", "Female", "Female")))
#> [1] Male Male Male Female Female
#> Levels: Male Female
## Using addNA()
Month <- airquality$Month
table(addNA(Month))
table(addNA(Month, ifany = TRUE))'Data > Manage variables in active data set' 카테고리의 다른 글
| 10. Define contrasts for a factor... (0) | 2022.02.10 |
|---|---|
| 9. Drop unused factor levels... (0) | 2022.02.10 |
| 6. Convert character variables to factors... (0) | 2022.02.10 |
| 12. Delete variables from data set... (0) | 2020.03.21 |
| 11. Rename variables... (0) | 2020.03.21 |