통계 > 차원 분석 > 군집 분석 > k-평균 군집 분석...
Statistics > Dimensional analysis > Cluster analysis > k-means cluster analysis...
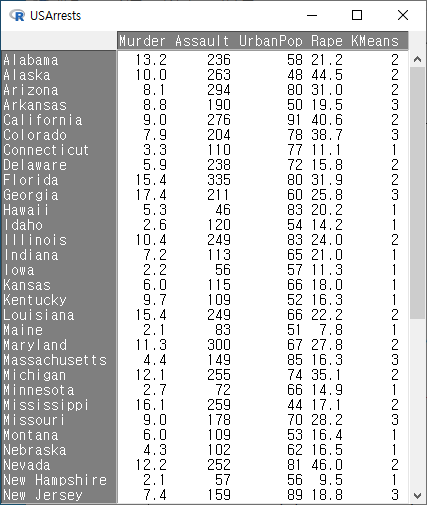
datasets 패키지에서 제공하는 USArrests 데이터셋을 이용해보자.
USArrests 데이터셋
datasets > USArrests data(USArrests, package="datasets") R Commander 화면 상단에서 <데이터셋 보기> 버튼을 누르면 아래와 같은 내부 구성을 확인할 수 있다. help("USArrests") USArrests {datasets} R Do..
rcmdr.kr
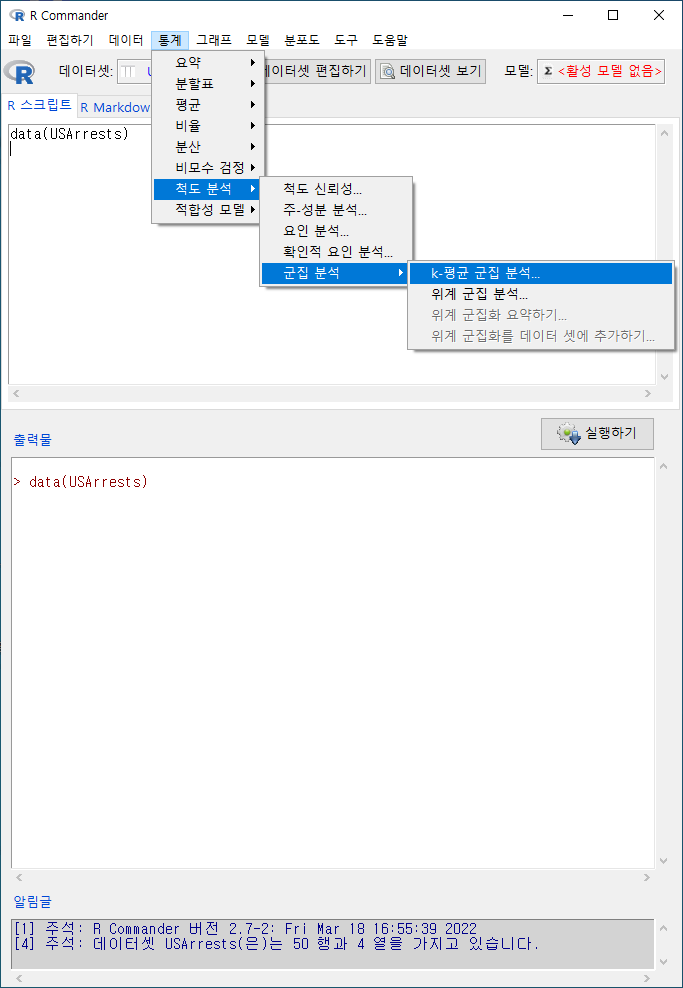
데이터셋에 포함된 네개의 변수를 모두 선택한다.
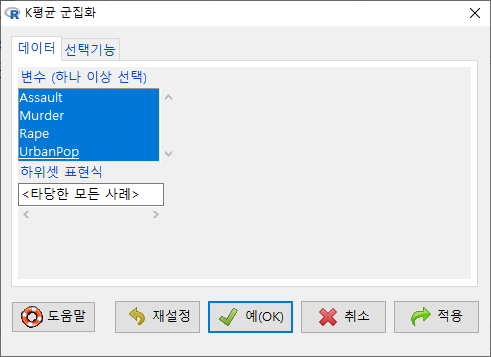
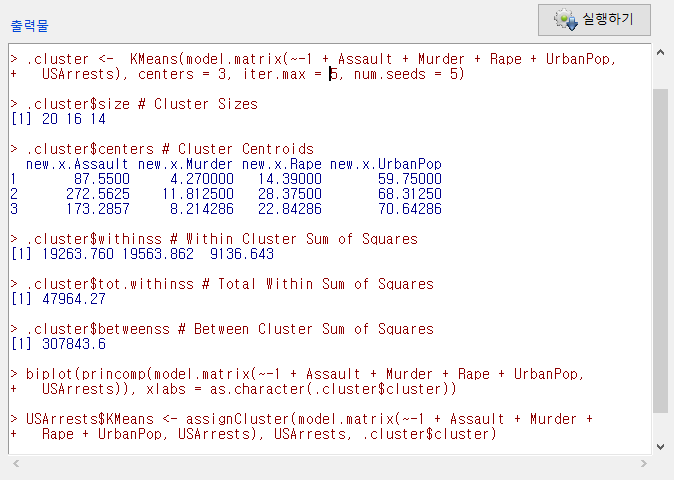
<선택기능> 창에서, 군집의 수를 3개, 초기값의 수를 5번으로, 최대 반복 횟수를 5회로 정해보자. 데이터셋에 추가될 변수 이름이 KMeans가 될 것이다. 아래 있는 선택사항에서 데이터셋에 군집 할당하기를 선택한다.
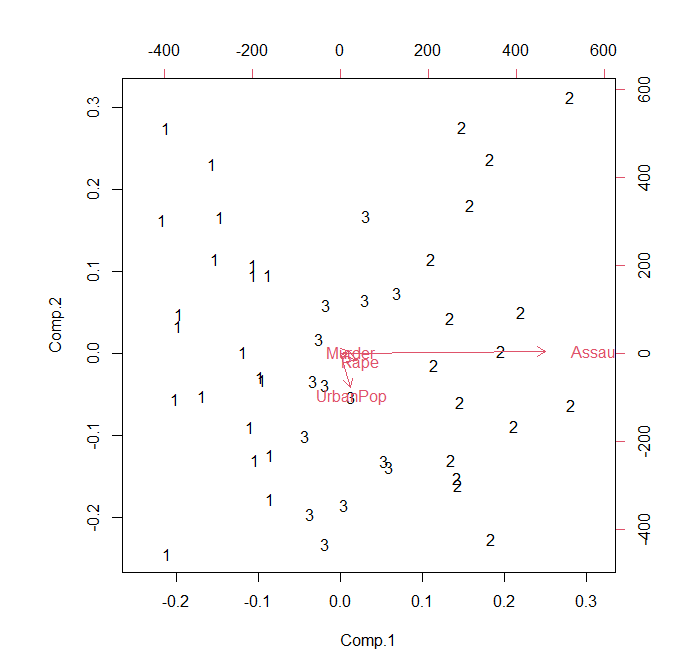
위 화면에서 선택된 군집 행렬도(Bi-plot)이 아래와 같이 생산된다.
USArrests 데이터셋에 변수 KMeans가 추가될 것이다. R Commander 상단에 있는 <데이터셋 보기> 버튼을 눌러보자. KMeans 변수는 요인형으로 1, 2, 3 이라는 세개의 군집을 표시한다.
아래 화면은 다소 복잡해보일 것이다. 그러나 객체 .cluster가 만들어졌으며, 그 객체안에 있는 $size, $withinss, $tot.withinss, $betweenss 등의 정보를 차례를 보여준다고 생각하자. 그리고 biplot을 생산하고, USArrests 데이터셋에 KMeans라는 변수를 추가하는 것이다.
'Statistics > Dimensional analysis' 카테고리의 다른 글
| 5.3. Summarize hierarchical clustering... (0) | 2022.03.20 |
|---|---|
| 5.2. Hierarchical cluster analysis... (0) | 2022.03.20 |
| 3. factor analysis... (0) | 2022.03.08 |
| 2. Principal-components analysis... (0) | 2022.03.08 |
| 1. Scale reliability... (0) | 2022.03.08 |