?swiss # swiss 데이터셋 도움말 보기
# 아래는 example(swiss) 입니다.
require(stats); require(graphics)
pairs(swiss, panel = panel.smooth, main = "swiss data",
col = 3 + (swiss$Catholic > 50))
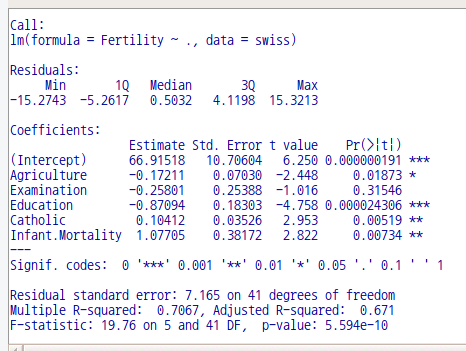
summary(lm(Fertility ~ . , data = swiss))
linux 사례 (MX 21)
pairs(swiss, panel = panel.smooth, main = "swiss data",
col = 3 + (swiss$Catholic > 50))
pairs(swiss, panel = panel.smooth, main = "swiss data") # 두 그래프를 비교해 보기
Linux 사례 (MX 21)Linux 사례 (MX 21)
LinearModel.1 <- lm(Fertility ~ . , data = swiss)
summary(LinearModel.1)
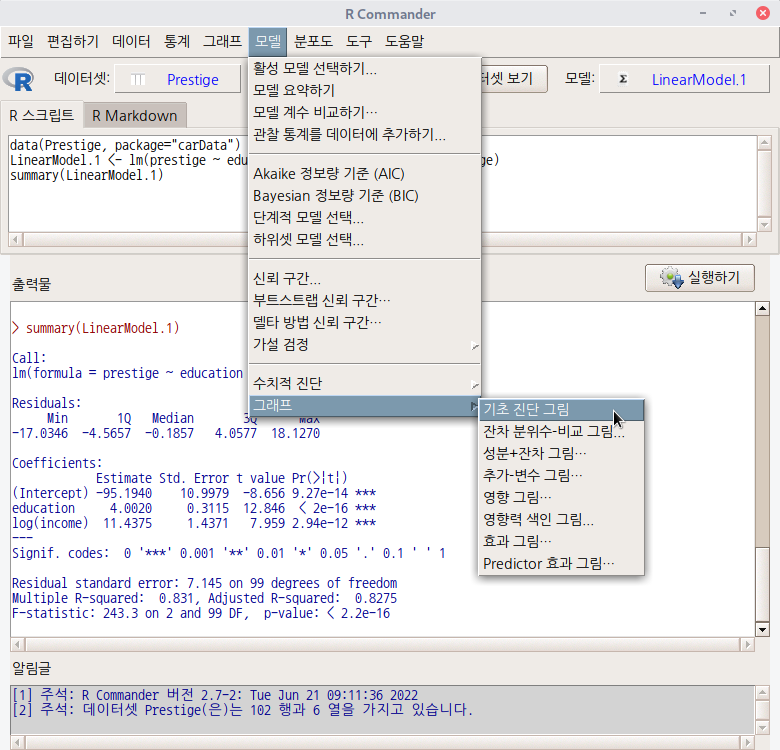
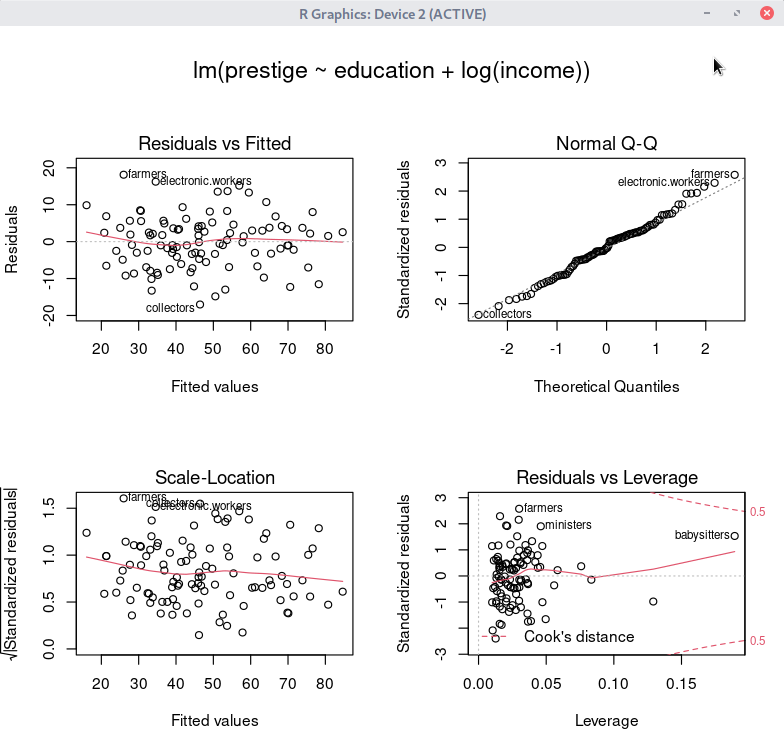
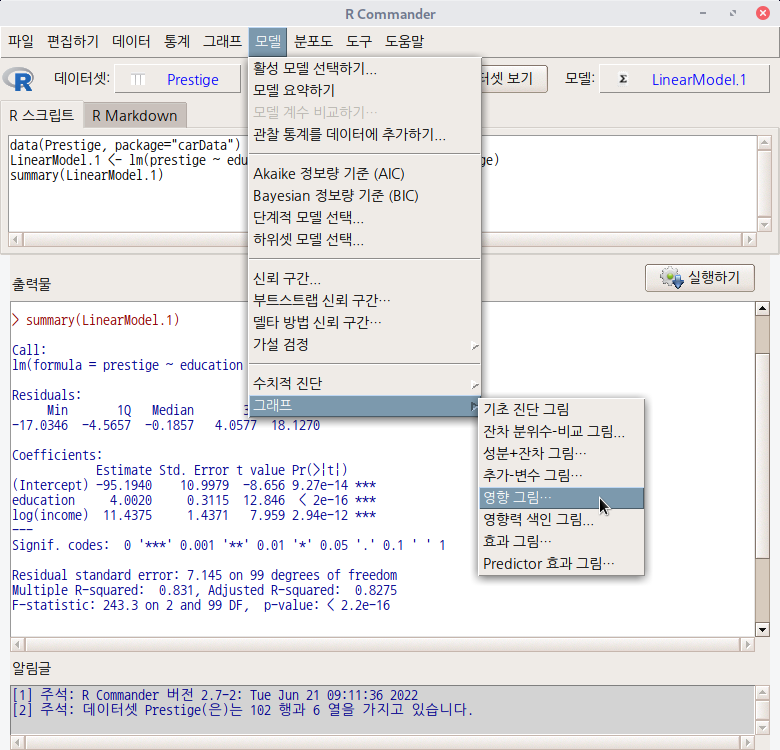
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > 기초 진단 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
모델 > 그래프 > Predictor 효과 그림... Models > Graphs > Predictor effect plots...
Linux 사례 (MX 21)
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > Predictor 효과 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
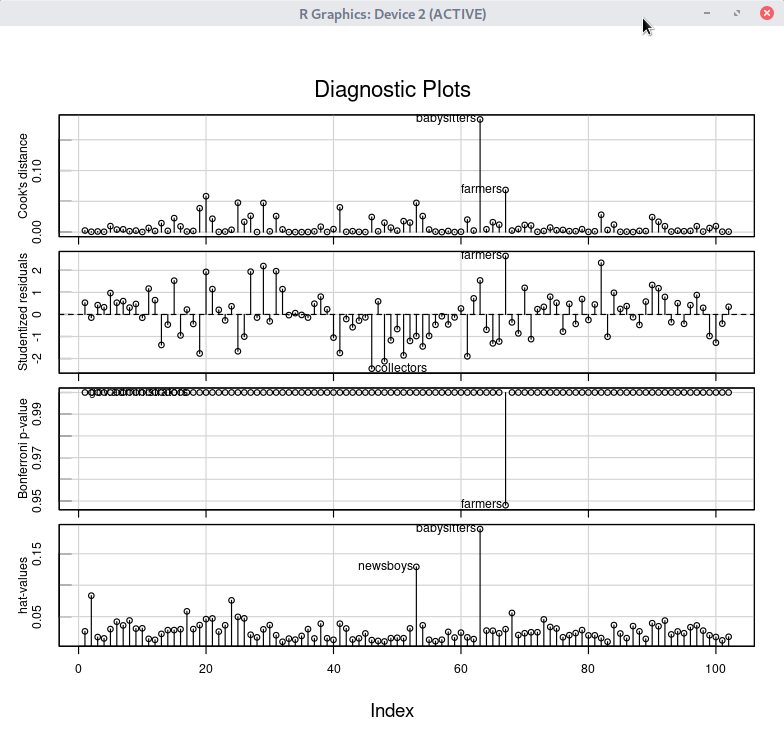
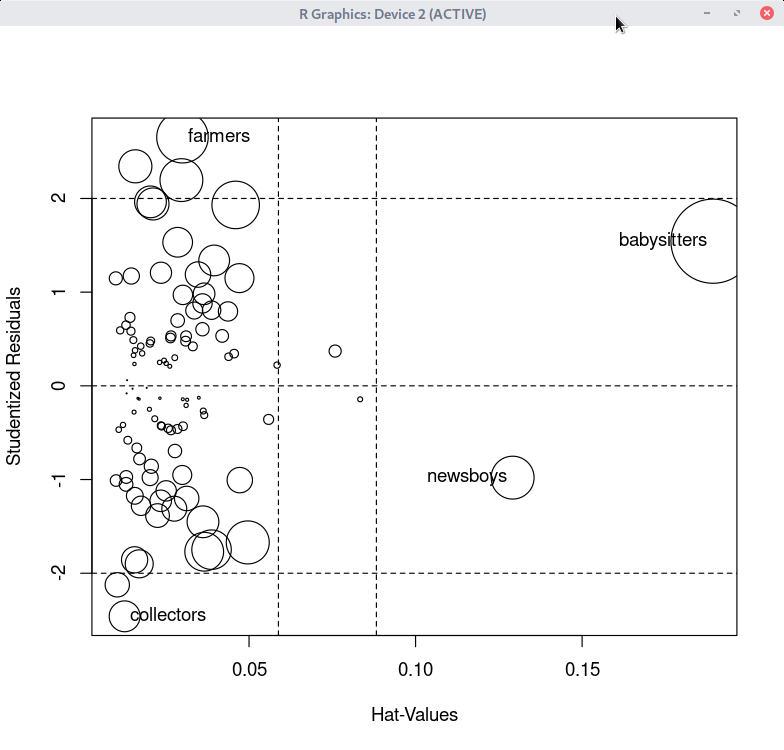
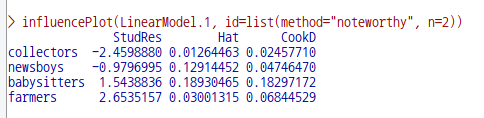
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > 영향력 색인 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
데이터셋을 활성화시키고, 분석 모형을 만들었다면, '모델 > 그래프 > 영향 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
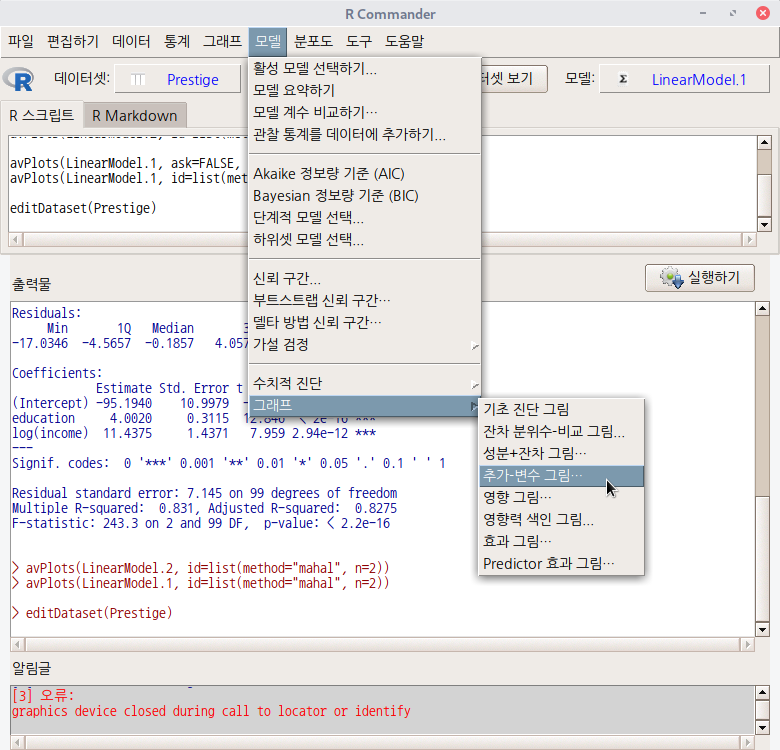
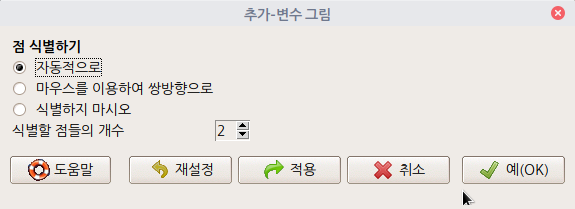
'모델 > 그래프 > 추가-변수 그림...' 메뉴 기능은 데이터셋이 활성화되고, 분석 모형이 만들어진 이후 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저, Prestige 데이터셋을 활성화 시키자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 carData 패키지에 포함된 데이터셋들 중에서 Prestige를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1 모형을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
회귀선에서 멀리 떨어져 있다고 추천된 2개의 사례들을 Prestige 데이터셋에서 제거해보자. general.managers가 중복되기 때문에 모두 3개의 사례가 삭제된다. 사례 삭제는 R Commander 상단에 있는 <데이터셋 편집하기> 버튼을 누르고 해당 사례를 찾아 삭제하는 방식을 취했다.
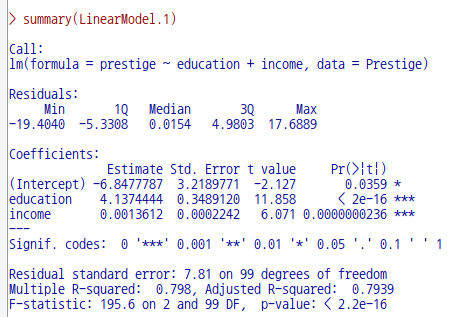
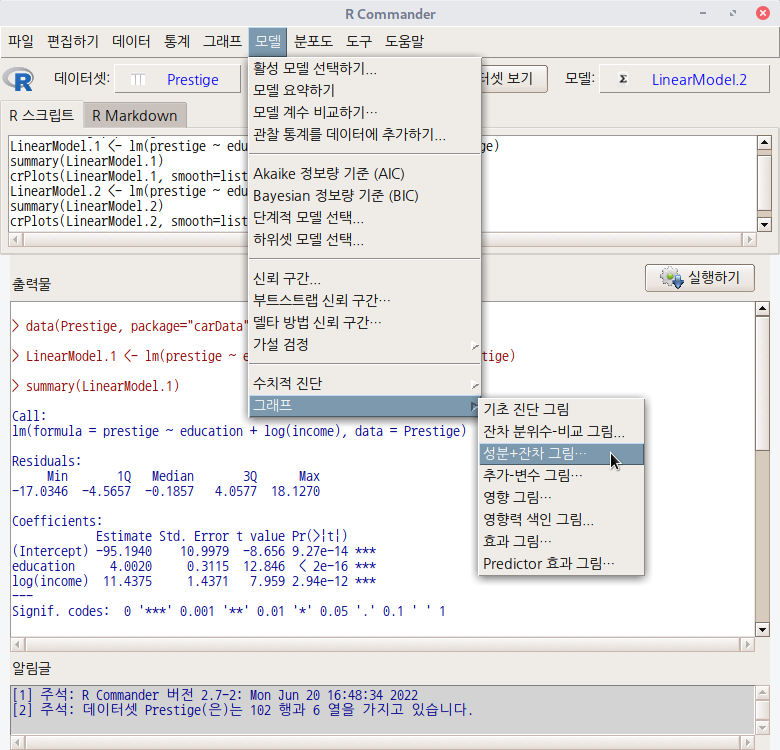
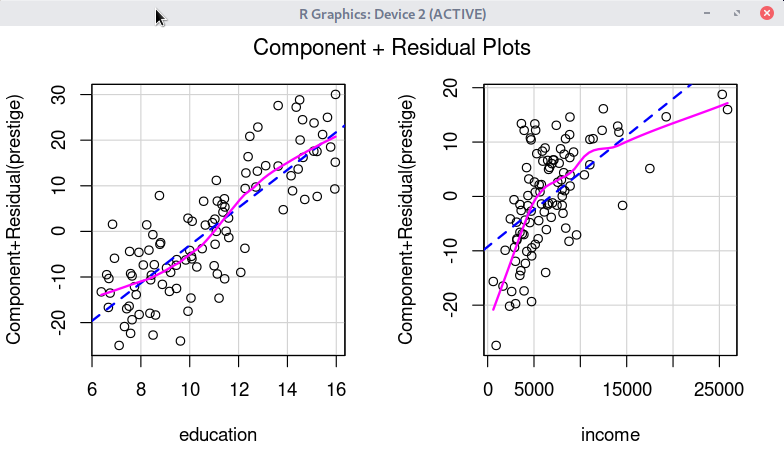
데이터셋이 활성화되고 통계적으로 분석된 모형이 만들어진 경우, '모델 > 그래프 > 성분 + 잔차 그림...' 메뉴 기능을 사용할 수 있다. carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자.
먼저 Prestige 데이터셋을 활성화 시킨다. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통해서 carData 패키지에서 Prestige 데이터셋을 찾아서 선택하면 된다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'Prestige'로 바뀐다.
Prestige 데이터셋을 이용하여 LinearModel.1, LinearModel.2 라는 두 개의 모형을 차례로 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 이용할 수 있다.
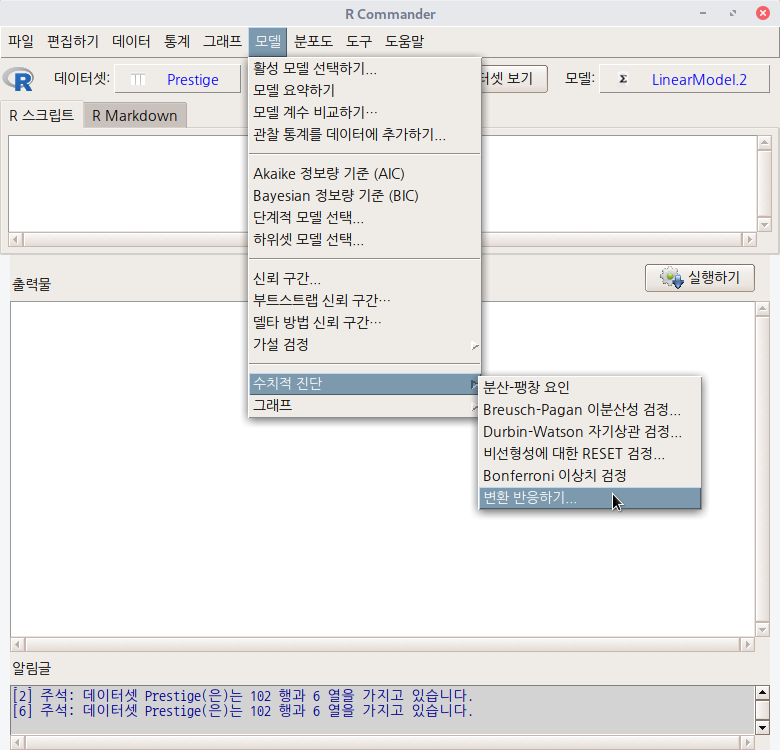
어느 데이터셋이 활성화되고, 그 데이터셋을 활용한 분석 모형이 만들어지면, '모델 > 수치적 진단 > 변환 반응하기...' 메뉴 창이 활성화된다.
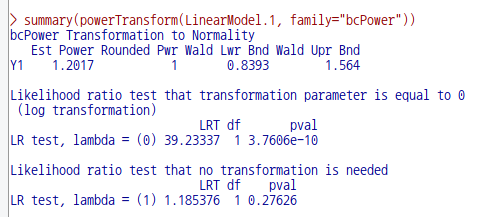
carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자. 먼저 Prestige 데이터셋을 활성화시킨다. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 carData 패키지에서 Prestige 데이터셋을 찾아서 선택한다. 다음, Prestige 데이터셋을 활용하여 선형 모델을 만든다. '통계 > 적합성 모델 > 선형 모델...' 메뉴 기능을 선택하여 모형을 만든다.