4. One-way ANOVA...
통계 > 평균 > 일원 분산 분석...
Statistics > Means > One-way ANOVA...
datasets 패키지에 있는 sleep 데이터셋을 활용해보자.
sleep
Datasets > sleep data(sleep, package="datasets") summary(sleep) str(sleep) 데이터셋의 내부는 다음과 같다:
rcmdr.kr
<집단 (하나 선택)>에 요인형 변수 group을, <반응 변수 (하나 선택)>에 수치형 변수 extra를 선택한다. 통계 > 분산 > 이-분산 F-검정을 통하여 비교되는 두 집단의 extra 변수의 사례 분포는 등분산임을 알고 있는 상황이다.
1. Two variances F-test...
통계 > 분산 > 이-분산 F-검정... Statistics > Variances > Two variances F-test... datasets 패키지에 포함된 sleep 데이터셋을 활용해보자. https://rcmdr.tistory.com/132 sleep data(sleep, package="datas..
rcmdr.kr

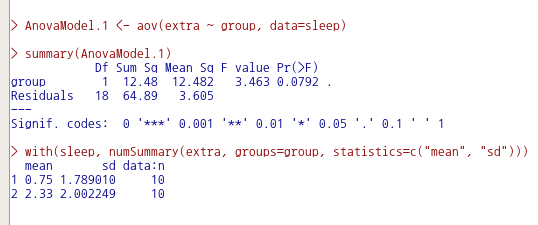
AnovaModel.1 <- aov(extra ~ group, data=sleep)
summary(AnovaModel.1)
with(sleep, numSummary(extra, groups=group, statistics=c("mean", "sd")))일원 분산 분석의 명령문 작성과 분석 결과는 아래와 같다.
추가로 carData 패키지의 Prestige 데이터셋을 이용하여 일원 분산 분석을 연습해보자. Prestige 데이터셋에는 type 이라는 요인형 변수가 있다. 그러나 앞서 연습한 sleep 데이터셋의 group 변수처럼 요인 수준이 두개가 아니라 요인의 수준이 셋이다. 직업의 사회적 권위에 대한 직업 유형별 (bc, prof, wc) 평균의 차이가 있는가를 점검한다.

AnovaModel.3 <- aov(prestige ~ type, data=Prestige)
summary(AnovaModel.3)
with(Prestige, numSummary(prestige, groups=type, statistics=c("mean", "sd")))직업유형 (bc, prof, wc)에 따른 직업의 사회적 권위는, 각 유형별 평균을 비교할 때, 차이가 있다는 결과를 얻는다.

?anova # stats 패키지의 anova 도움말 보기