통계 > 적합성 모델 > 선형 회귀...
Statistics > Fit models > Linear regression...
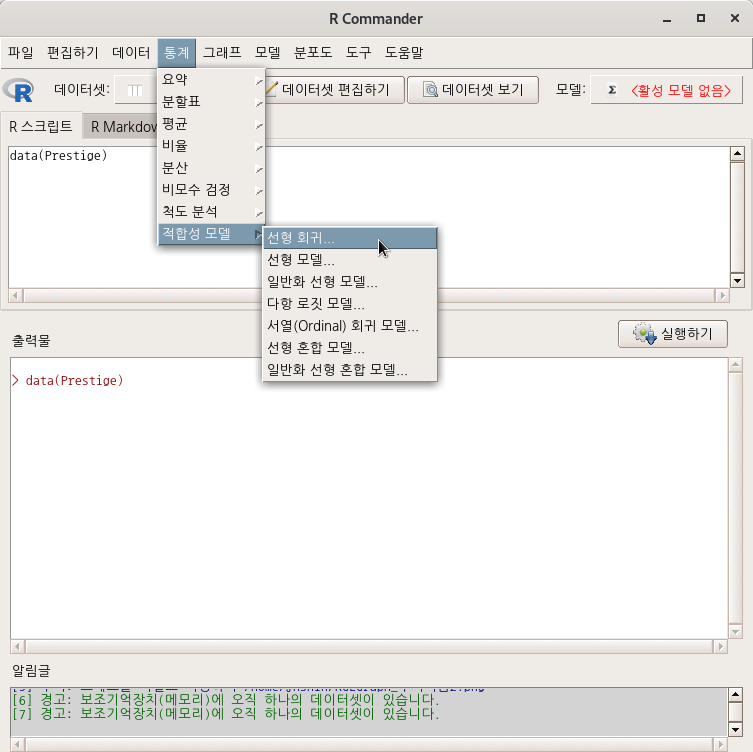
carData 패키지에서 제공하는 Prestige 데이터셋을 불러와서 활성화시키자. 그러면, 위의 화면처럼 <선형 회귀...> 기능이 활성화될 것이다. 이 기능을 선택하면 아래와 같이 Prestige 데이터셋의 변수 목록이 등장하며, 회귀분석을 위한 구조적 설계를 시작한다.
교육연수(education)와 연소득(income)이 직업의 사회적권위(prestige)에 영향을 미치는가? 어떤 영향을 미치는가? 등의 문제의식을 통계적으로 점검한다고 해보자. 교육연수와 연소득은 설명 변수일 것이며, 직업의 사회적 권위는 이 두개의 설명 변수로부터 영향을 받는 반응 변수가 될 것이다. 한편, <모델 이름 입력하기:>에는 RegModel.1이 자동적으로 추천된다. 여러 개의 모델을 만들어 점검하는 경우, 지속적으로 일련번호가 추가된다. 분석가가 자유롭게 모델 이름을 정할 수 있다.
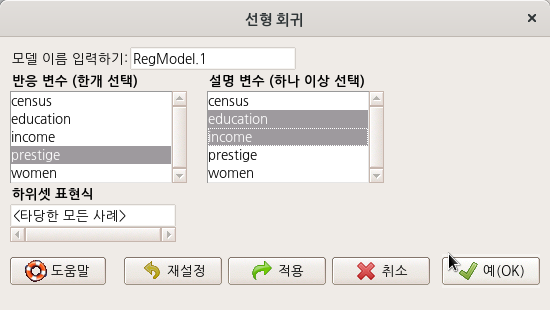
예(OK) 버튼을 누르면, R Commander 화면 상단에 있는 <모델:>옆에 파란색으로 RegModel.1이 등장한다.

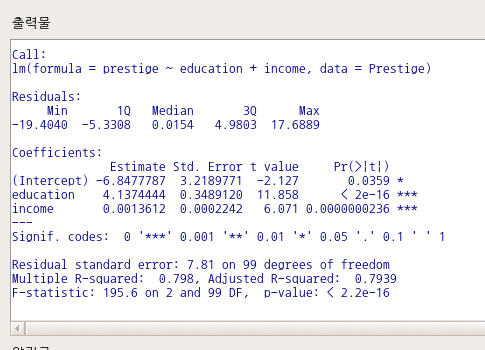
RegModel.1 <- lm(prestige~education+income, data=Prestige)
summary(RegModel.1)R Commander의 출력 창에는 만든 선형 회귀 모델의 결과가 출력된다.
'Statistics > Fit models' 카테고리의 다른 글
| 5. Ordinal regression model... (0) | 2022.06.24 |
|---|---|
| 6. Linear mixed model... (0) | 2022.06.23 |
| 4. Multinomial logit model... (0) | 2022.03.09 |
| 3. Generalized linear model... (0) | 2022.03.09 |
| 2. Linear model... (0) | 2022.03.07 |